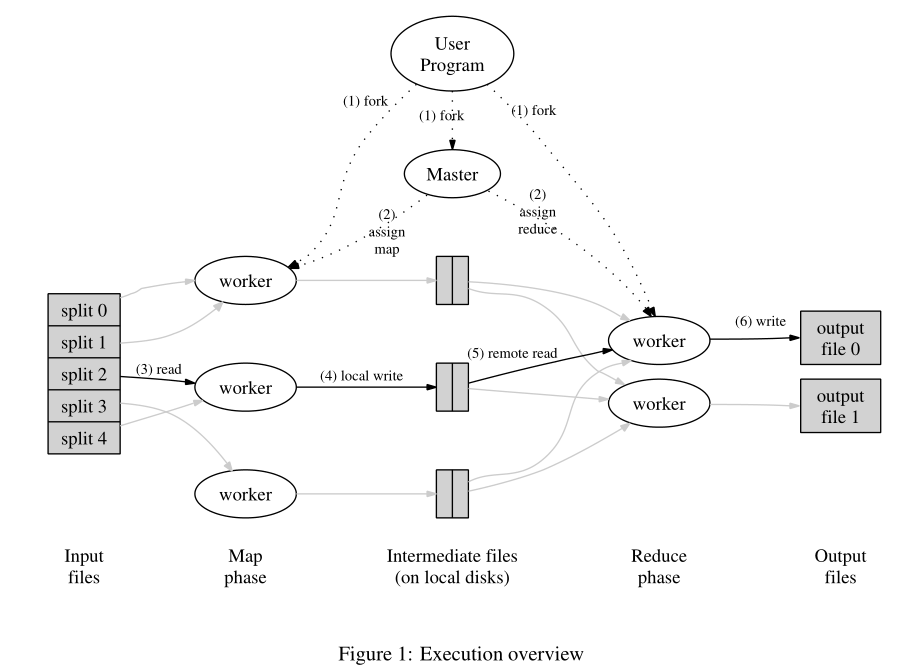
MapReduce 基于《MapReduce: Simplified Data Processing on Large Clusters》和Mit 6.824课程,以go语言 实现了 单机多进程 的 MapReduce 框架。通过设计实现Master主节点、Worker工作节点以及两者之间的RPC通信 ,模拟了分布式环境下的调度执行程序,错误恢复 ,以及管理所需的机器间通信。并通过该框架统计一个很大的文档集合中每个单词出现的次数。
特点
设计实现了MapReduce论文中的Master主节点,将M个map任务和R个reduce任务分配给空闲的工作节点,通过维护任务管道 调度所有任务的运行,同时在分发任务的过程中进行互斥锁 的添加与回退,防止多个worker竞争。
设计实现了MapReduce论文中的Worker工作节点,Worker节点可以在空闲时请求任务池里的任务,对相应的Map任务和Reduce任务进行解析并计算。对于Map任务读取对应的输入区块内容,计算解析出key/value对并缓存在本机;对于Reduce任务使用RPC调用得到Map工作节点的本地磁盘中的缓存数据,遍历并通过shuffle方法 排序好所有的缓存数据,之后根据重排序好key/value数组重定向输出文件。
设计实现了错误恢复机制,通过中间文件存储和在Master开启一个协程追踪任务进行时间戳的方式,保证当Worker正在执行任务时突然宕机和卡死等情况下被执行的任务能够重新恢复并调度给其他空闲的工作节点。
详细设计过程 项目框架
src/mrapps下是各种使用框架的用户编写好的map和reduce函数,比如wc.go是针对统计文件中各单词出现次数问题的map和reduce函数。
src/mr下是我们要编写的master.go、rpc.go、worker.go代码,也就是简易版的mapreduce框架的代码,src/mr就是该简易框架的包;之后要运行的主程序会调用这个mr包的代码。
src/main下的mrmaster.go是master的主进程代码,运行一次该代码就产生一个master进程,mrworker.go是worker的主进程代码,运行一次该代码就产生一个worker进程。因此,我们在写程序的过程中可以使用这里的主进程代码进行编写编输出打印信息或者调试。
设计思路 本次实验是实现在单机上的,因此文件的分布会稍有些不同,如下图是本次实验的文件流向图,首先将文档分成 m 份,每一份调用一个 map 函数操作并生成 n 个文件 。所有 map 操作完成后进行 reduce 操作,对于 每个reduce 操作,从上一步生成 的mn 个文件中选取 对应的 m 个文件 进行reduce 操作,完成后将结果写入 Mi 中。 所有 reduce 操作完成后将 n 个临时文件合并成最终的 output 文件。
1. 参考MapReduce论文,先查看实验文件中提供的示例mrsequential.go,它提供了一种非分布式的实现map function和reduce function,完成对应的读取mr/main中的pg-xxx.txt,进行分词得到对应的kv对,存入intermediate中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 intermediate := []mr.KeyValue{} for _, filename := range os.Args[2 :] { file, err := os.Open(filename) if err != nil { log.Fatalf("cannot open %v" , filename) } content, err := ioutil.ReadAll(file) if err != nil { log.Fatalf("cannot read %v" , filename) } file.Close() kva := mapf(filename, string (content)) intermediate = append (intermediate, kva...) }
对intermediate进行排序
1 sort.Sort(ByKey(intermediate))
实现reduce函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 i := 0 for i < len (intermediate) { j := i + 1 for j < len (intermediate) && intermediate[j].Key == intermediate[i].Key { j++ } values := []string {} for k := i; k < j; k++ { values = append (values, intermediate[k].Value) } output := reducef(intermediate[i].Key, values) fmt.Fprintf(ofile, "%v %v\n" , intermediate[i].Key, output) i = j }
有了该示例,我们查看main中的其他代码,mrworker.go和mrcoordinator.go中都分别调用了对应mr包里的worker和coordinator对象,因此需要去mr/worker.go和mr/coordinator.go中定义这两个对象,并且完成对应的初始化工作
完成了初始化后,进行mapReduce的第2步【assign map/reduce】,master向worker分配任务
这一步的实现需要worker通过rpc调用,实验的示例代码中也有rpc调用的示例过程。worker在返回response之后开始解析任务。
worker开始解析任务之前,需要知道任务的类型,那么就需要设计一个Task结构体,里面有一个变量为TaskType 用来表明当前任务的类型。
由4分析我们知道,对于coordinator而言,需要保存所有的task,对于每一个task而言,需要有这个task对应的状态(Working/Waiting/Done),同时,coordinator需要有两个队列,一个为Map队列,一个为Reduce队列,分别存放两种不同类型的任务。
Map队列的大小为所有文件的个数。
Reduce队列的大小为coordinator指定的nRedcue。
在初始化的时候,需要将上述队列初始化。
需要在coordinator中实现一个rpc服务进行任务的分配,让worker可以直接调用。
coordinator需要知道map任务的完成情况,参考实验示例,worker在完成任务之后调用一个callDone(),调用一个rpc服务向coordinator报告自己对应任务以及完成。
完成了所有的任务后,worker和coordinator的退出也需要进行考虑,实验提示中给出了两种方法,一种是coordinator退出后,worker的rpc失败退出;另一种是master在看到map和reduce任务都已经完成后,发出一个假任务标志,worker收到后主动退出。第一种的实现可以在worker里写一个死循环,不断地向coordinator调用任务分配的rpc,如果coordinator返回空响应,则表明任务完成,退出寻呼按。第二种的实现比较简单,只需要在coordinator中添加DistPhase变量,用来表明目前整个框架应该处于什么任务阶段,如果是Exit,退出即可。本次实验我选择的是第二种实现。
具体实现 数据结构 完成了初步的思考与设计之后,我先设计了Task和Coordinator的数据结构:
Task
Task的结构体中,需要有当前的任务类型,当前的任务id,以及输入文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 type Task struct { TaskType TaskType TaskId int ReducerNum int FileSlice []string } type TaskArgs struct {}type TaskType int type Phase int type State int const ( MapTask TaskType = iota ReduceTask WaittingTask ExitTask ) const ( MapPhase Phase = iota ReducePhase AllDone ) const ( Working State = iota Waiting Done )
Coordinator
reduce队列和map队列我在这里是用go中的通道实现,它同样遵循先进先出的规则,对于所有task的存放,采用一个taskMetaHolder,它来保存全部任务的元数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 type Coordinator struct { ReducerNum int TaskId int DistPhase Phase ReduceTaskChannel chan *Task MapTaskChannel chan *Task taskMetaHolder TaskMetaHolder files []string } type TaskMetaHolder struct { MetaMap map [int ]*TaskMetaInfo } type TaskMetaInfo struct { state State StartTime time.Time TaskAdr *Task }
RPC通信 在实验中RPC通信主要有两个模块,分别为
Worker 在空闲时向 Coordinator 发起 Task 请求,Coordinator 响应一个分配给该 Worker 的 Task
Worker 在上一个 Task 运行完成后向 Coordinator 汇报,Coordinator 响应之后标记该任务完成
因此需要在worker中编写相应的请求
发起Task请求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func GetTask () args := TaskArgs{} reply := Task{} ok := call("Coordinator.PollTask" , &args, &reply) if ok { } else { fmt.Printf("call failed!\n" ) } return reply }
发起标记任务结束请求
1 2 3 4 5 6 7 8 9 10 11 12 func callDone (f *Task) args := f reply := Task{} ok := call("Coordinator.MarkFinished" , &args, &reply) if ok { } else { fmt.Printf("call failed!\n" ) } return reply }
Coordinator 首先需要维护以下信息:
基础的配置信息(输入、总的Map Task、总的Reduce Task)
单个Task的状态信息
当前整个框架的阶段(是在分发Map/等待/分发Reduce/结束)
调度信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 func MakeCoordinator (files []string , nReduce int ) c := Coordinator{ files: files, ReducerNum: nReduce, DistPhase: MapPhase, MapTaskChannel: make (chan *Task, len (files)), ReduceTaskChannel: make (chan *Task, nReduce), taskMetaHolder: TaskMetaHolder{ MetaMap: make (map [int ]*TaskMetaInfo, len (files)+nReduce), }, } c.makeMapTasks(files) c.server() go c.CrashDetector() return &c }
除了维护以上信息,Coordinator 还需要完成以下过程:
对Map Task进行处理与初始化,并将这些Map Task放置在MapTaskChannel中
对Reduce Task进行处理与初始化,并将这些Reduce Task放置在ReduceTaskChannel中
响应Worker的Task请求,根据当前框架的阶段分发Task
响应Worker的任务完成请求,对响应的Task进行标记
在Map Task全部完成后,将当前框架的阶段从MapPhase转移至ReducePhase(Reduce阶段)
在Reduce Task全部完成后,标记当前框架任务全部完成,退出
进行故障检测,在任务执行的过程中开启一个故障检测协程,将超过10s的任务都放回chan中,等待任务重新读取。
对Map Task进行初始化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func (c *Coordinator) string ) { for _, v := range files { id := c.generateTaskId() task := Task{ TaskType: MapTask, TaskId: id, ReducerNum: c.ReducerNum, FileSlice: []string {v}, } taskMetaInfo := TaskMetaInfo{ state: Waiting, TaskAdr: &task, } c.taskMetaHolder.acceptMeta(&taskMetaInfo) c.MapTaskChannel <- &task } }
生成唯一id的方法:
1 2 3 4 5 6 7 func (c *Coordinator) int { res := c.TaskId c.TaskId++ return res }
将taskMetaInfo放到taskMetaHolder中的具体方法:
1 2 3 4 5 6 7 8 9 10 11 func (t *TaskMetaHolder) bool { taskId := TaskInfo.TaskAdr.TaskId meta, _ := t.MetaMap[taskId] if meta != nil { return false } else { t.MetaMap[taskId] = TaskInfo } return true }
对Reduce Task进行初始化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 func (c *Coordinator) for i := 0 ; i < c.ReducerNum; i++ { id := c.generateTaskId() task := Task{ TaskId: id, TaskType: ReduceTask, FileSlice: selectReduceName(i), } taskMetaInfo := TaskMetaInfo{ state: Waiting, TaskAdr: &task, } c.taskMetaHolder.acceptMeta(&taskMetaInfo) c.ReduceTaskChannel <- &task } }
响应Worker的Task请求,分发任务 在PollTask中Coordinator会先根据当前MapReduce的阶段分发Task。
如果当前是Map阶段,则Coordinator会将map任务管道中的任务取出,如果取不出来,说明任务已经取尽,那么此时任务要么就已经完成,要么就是正在进行 。Coordinatorh会把返回的task标记为Waitting,并检查当前任务的完成情况[checkTaskDone],如果所有任务都做完了,那么进入下一阶段[toNextPhase]。
如果当前是Reduce阶段,Coordinator会将Reduce任务管道中的任务取出,之后同Map阶段。
如果当前是Exit阶段,则返回任务阶段标记为Exit,Worker收到该任务后会自动退出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 func (c *Coordinator) error { mu.Lock() defer mu.Unlock() switch c.DistPhase { case MapPhase: { if len (c.MapTaskChannel) > 0 { *reply = *<-c.MapTaskChannel if !c.taskMetaHolder.judgeState(reply.TaskId) { fmt.Printf("Map-taskid[ %d ] is running\n" , reply.TaskId) } } else { reply.TaskType = WaittingTask if c.taskMetaHolder.checkTaskDone() { c.toNextPhase() } return nil } } case ReducePhase: { if len (c.ReduceTaskChannel) > 0 { *reply = *<-c.ReduceTaskChannel if !c.taskMetaHolder.judgeState(reply.TaskId) { fmt.Printf("Reduce-taskid[ %d ] is running\n" , reply.TaskId) } } else { reply.TaskType = WaittingTask if c.taskMetaHolder.checkTaskDone() { c.toNextPhase() } return nil } } case AllDone: { reply.TaskType = ExitTask } default : panic ("The phase undefined ! ! !" ) } return nil }
分配任务中转换阶段的实现:
1 2 3 4 5 6 7 func (c *Coordinator) if c.DistPhase == MapPhase { c.makeReduceTasks() c.DistPhase = ReducePhase } else if c.DistPhase == ReducePhase { c.DistPhase = AllDone }
分配任务中检查任务是否完成的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 func (t *TaskMetaHolder) bool { var ( mapDoneNum = 0 mapUnDoneNum = 0 reduceDoneNum = 0 reduceUnDoneNum = 0 ) for _, v := range t.MetaMap { if v.TaskAdr.TaskType == MapTask { if v.state == Done { mapDoneNum++ } else { mapUnDoneNum++ } } else if v.TaskAdr.TaskType == ReduceTask { if v.state == Done { reduceDoneNum++ } else { reduceUnDoneNum++ } } } if (mapDoneNum > 0 && mapUnDoneNum == 0 ) && (reduceDoneNum == 0 && reduceUnDoneNum == 0 ) { return true } else { if reduceDoneNum > 0 && reduceUnDoneNum == 0 { return true } } return false }
分配任务中修改任务的状态方法:
1 2 3 4 5 6 7 8 9 10 func (t *TaskMetaHolder) int ) bool { taskInfo, ok := t.MetaMap[taskId] if !ok || taskInfo.state != Waiting { return false } taskInfo.state = Working taskInfo.StartTime = time.Now() return true }
响应任务完成请求 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 func (c *Coordinator) error { mu.Lock() defer mu.Unlock() switch args.TaskType { case MapTask: meta, ok := c.taskMetaHolder.MetaMap[args.TaskId] if ok && meta.state == Working { meta.state = Done } else { fmt.Printf("Map task Id[%d] is finished,already ! ! !\n" , args.TaskId) } break case ReduceTask: meta, ok := c.taskMetaHolder.MetaMap[args.TaskId] if ok && meta.state == Working { meta.state = Done } else { fmt.Printf("Reduce task Id[%d] is finished,already ! ! !\n" , args.TaskId) } break default : panic ("The task type undefined" ) } return nil }
故障检测 在初始化协调者的时候同步开启一个crash探测协程,将超过10s的任务都放回chan中,等待任务重新读取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func (c *Coordinator) for { time.Sleep(time.Second * 2 ) mu.Lock() if c.DistPhase == AllDone { mu.Unlock() break } for _, v := range c.taskMetaHolder.MetaMap { if v.state == Working && time.Since(v.StartTime) > 9 *time.Second { switch v.TaskAdr.TaskType { case MapTask: c.MapTaskChannel <- v.TaskAdr v.state = Waiting case ReduceTask: c.ReduceTaskChannel <- v.TaskAdr v.state = Waiting } } } mu.Unlock() } }
Worker Worker的核心是一个死循环,当没有接受到Exit State的Task时,不断地向 Coordinator 调用 Task请求的RPC
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 func Worker (mapf func (string , string ) func (string , []string ) string ) { keepFlag := true for keepFlag { task := GetTask() switch task.TaskType { case MapTask: { DoMapTask(mapf, &task) callDone(&task) } case WaittingTask: { time.Sleep(time.Second * 5 ) } case ReduceTask: { DoReduceTask(reducef, &task) callDone(&task) } case ExitTask: { time.Sleep(time.Second) fmt.Println("All tasks are Done ,will be exiting..." ) keepFlag = false } } } time.Sleep(time.Second) }
除了发起Task请求,在Worker中还需要设计对应的Map函数和Reduce函数
Map函数 参考给定的wc.go、mrsequential.go的map方法,编写属于自己 的map方法,这里简述下流程:插件编辑进来的mapf方法处理Map生成一组kv,然后写到temp文件中,temp命名采用mr-tmp-{taskId}-ihash(kv.Key),调用的库为文档推荐的json库。至于为什么采用中间文件,其实也是为了后面crash有关,这个在后面crash部分再提。
通过main/mrworker中的loadPlugin得到的mapf方法处理文件,得到一组kv。将这组kv通过ihash(key)%nReduce的方式存放在对应的nReduce分区。之后用实验提示中的json库的方式生成中间文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 func DoMapTask (mapf func (string , string ) var intermediate []KeyValue filename := response.FileSlice[0 ] file, err := os.Open(filename) if err != nil { log.Fatalf("cannot open %v" , filename) } content, err := ioutil.ReadAll(file) if err != nil { log.Fatalf("cannot read %v" , filename) } file.Close() intermediate = mapf(filename, string (content)) rn := response.ReducerNum HashedKV := make ([][]KeyValue, rn) for _, kv := range intermediate { HashedKV[ihash(kv.Key)%rn] = append (HashedKV[ihash(kv.Key)%rn], kv) } for i := 0 ; i < rn; i++ { oname := "mr-tmp-" + strconv.Itoa(response.TaskId) + "-" + strconv.Itoa(i) ofile, _ := os.Create(oname) enc := json.NewEncoder(ofile) for _, kv := range HashedKV[i] { err := enc.Encode(kv) if err != nil { return } } ofile.Close() } }
Reduce函数 Worker在Reduce中对之前的tmp文件进行shuffle,得到一组排序好的kv数组,并根据重排序好kv数组重定向输出文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 func DoReduceTask (reducef func (string , []string ) string , response *Task) { reduceFileNum := response.TaskId intermediate := shuffle(response.FileSlice) dir, _ := os.Getwd() tempFile, err := ioutil.TempFile(dir, "mr-tmp-*" ) if err != nil { log.Fatal("Failed to create temp file" , err) } i := 0 for i < len (intermediate) { j := i + 1 for j < len (intermediate) && intermediate[j].Key == intermediate[i].Key { j++ } var values []string for k := i; k < j; k++ { values = append (values, intermediate[k].Value) } output := reducef(intermediate[i].Key, values) fmt.Fprintf(tempFile, "%v %v\n" , intermediate[i].Key, output) i = j } tempFile.Close() fn := fmt.Sprintf("mr-out-%d" , reduceFileNum) os.Rename(tempFile.Name(), fn) }
shuffle方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 func shuffle (files []string ) var kva []KeyValue for _, filepath := range files { file, _ := os.Open(filepath) dec := json.NewDecoder(file) for { var kv KeyValue if err := dec.Decode(&kv); err != nil { break } kva = append (kva, kv) } file.Close() } sort.Sort(SortedKey(kva)) return kva }
碰撞检测 此外 Lab 要求我们考虑 Worker 的 Failover,即 Worker 获取到 Task 后可能出现宕机和卡死等情况。这两种情况在 Coordinator 的视角中都是相同的,就是该 Worker 长时间不与 Coordinator 通信了。为了简化任务,Lab 说明中明确指定了,设定该超时阈值为 10s 即可。为了支持这一点,我们的实现需要支持到:
Coordinator 追踪已分配 Task 的运行情况,在 Task 超出 10s 仍未完成时,将该 Task 重新分配给其他 Worker 重试
考虑 Task 上一次分配的 Worker 可能仍在运行,重新分配后会出现两个 Worker 同时运行同一个 Task 的情况。要确保只有一个 Worker 能够完成结果数据的最终写出,以免出现冲突,导致下游观察到重复或缺失的结果数据
第一点比较简单,而第二点会相对复杂些,不过在 Lab 文档中也给出了提示 —— 实际上也是参考了 Google MapReduce 的做法,Worker 在写出数据时可以先写出到临时文件,最终确认没有问题后再将其重命名为正式结果文件,区分开了 Write 和 Commit 的过程。Commit 的过程可以是 Coordinator 来执行,也可以是 Worker 来执行:
Coordinator Commit:Worker 向 Coordinator 汇报 Task 完成,Coordinator 确认该 Task 是否仍属于该 Worker,是则进行结果文件 Commit,否则直接忽略
Worker Commit:Worker 向 Coordinator 汇报 Task 完成,Coordinator 确认该 Task 是否仍属于该 Worker 并响应 Worker,是则 Worker 进行结果文件 Commit,再向 Coordinator 汇报 Commit 完成
这里两种方案都是可行的,各有利弊。我在我的实现中选择了 Coordinator Commit,因为它可以少一次 RPC 调用,在编码实现上会更简单,但缺点是所有 Task 的最终 Commit 都由 Coordinator 完成,在极端场景下会让 Coordinator 变成整个 MR 过程的性能瓶颈。