BusTub
BusTub是卡内基梅隆大学CMU 15-445的课程Lab,该Lab是在一个基础的框架上实现储存引擎的各项主要功能。为BusTub DBMS构建一个新的面向磁盘的存储管理器,该存储管理器假定数据库的主要存储位置在磁盘上。
特点
- 基于LRU策略的缓冲池
- 索引方式:动态哈希
Lab1 BUFFER POOL
第一个Lab为存储引擎实现缓冲池(Buffer Pool)。缓冲池负责将物理页面从主内存来回移动到磁盘。它允许 DBMS 支持大于系统可用内存量的数据库。缓冲池的操作对系统中的其他部分是透明的,系统使用其唯一标识符 (page_id_t)向缓冲池请求页面。
技术点
- 使用互斥锁保证缓冲池的线程安全性,允许多个线程同时访问内部数据结构。
- 使用LRU的缓存替换策略,以减少磁盘IO次数,提高性能。
- 使用闩锁(latch)完成并行的Buffer Pool,避免单个Buffer Pool情形下每个线程与缓冲池交互时都进行资源争夺。
实现细节
LRU的实现:
- 页面需要使用一个数据结构来存储,考虑到需要不断地进行插入操作(头插)和删除操作(尾删),因此选择使用双向链表。但为了更快地查找速度,增加一个哈希表,以双向链表+哈希表实现O(1)的查找速度。
- 双向链表负责维护一个Page的集合。按照链表头部为最近使用过的Page进行排序。每当更新一个页面,都会将其放在双向链表头部,即便是某个页面已经在链表中,也要拿出来重新放置。每当置换的时候,都会从双向链表的尾部置换页面,删除最近没有使用的页面。
- 哈希表负责维护一个Page到链表节点的映射。它的作用有两个,一个是方便查找某个页面当前是否在这个链表当中。另一个是能够快速定位到当前页面在链表中的位置,方便删除操作。
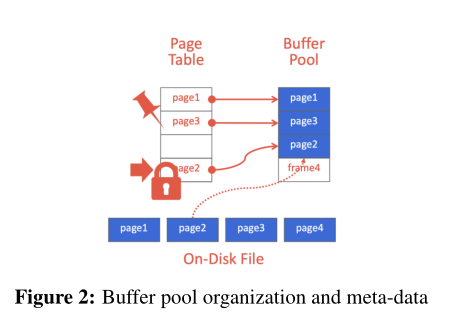
BufferPoolManager的实现:
- BufferPoolManager需要完成在缓冲池中对Page的分配/移除,从缓冲池中获取请求的Page,将Page写入磁盘。
- BufferPoolManager实现上述功能需要存储在磁盘的Page进行访问/管理,DBMS 会维护一个 page table,负责记录每个 page 在内存中的位置,以及是否被写过(Dirty Flag),是否被引用或引用计数(Pin/Reference Counter)等元信息,BufferPoolManager通过存放所有page的page_数组作为基地址,加上frame_id作为偏移量,就可以以基地址+偏移量的方式获得目标Page,本质上是数组寻址
- 对Page的分配需要确定Buffer pool中有未被Pin的Page,之后依据先前实现的LRU Replacer获得置换后的page_id,将该page_id对应的Page初始化后就可以分配为新的Page。
- Page写入磁盘依赖DiskManager,其提供了WritePage方法,只需要在写入前得到写入Page的page_id,再由哈希表page_table得到frame_id的映射。
保证缓冲池线程安全性(thread safe):
- 当一个Page被读取时候,一个并发的线程将这个Page驱逐,并用一个不同的Page替换它,读取旧Page内容的进程(reader)将看到不正确的数据;如果Page被驱逐时正在写入它,那么写入者最终会破坏替换Page的内容。因此引入在线程对Page进行读/写时进行Pin操作,避免出现上述情况。
- BufferPoolManager不清除固定的Page(pin值不为0的块)。当进程完成读取数据时,它应该执行一个Unpin操作,允许在需要时将Page取出,同时BufferPoolManager还维护Page数据结构的pin_count_字段来记录pin的数量。
- 通过在Victim、Pin、Unpin函数中加上互斥锁保证线程安全。
ParallelBufferPoolManager的实现:
- 单个缓冲池管理器可能会照成大量的锁争用,因为在这种情况下每个线程和缓冲池交互都争着用单个锁存器,因此需要实现一个并行管理器来管理多个缓冲池管理器,进而实现每个缓冲池都有自己的latch
- 通过轮询的策略可以减少锁的竞争。在面对请求时,采用Round-Robin策略来选择一个buffer pool instance制造页面。Parallel Buffer Pool维护一个start_index的变量,每次k从start_index出发,当知道有一个instance返回了不为空的page指针,再把start_index置为当前k加1即可,通过模的方式可以保证start_index始终在[0,num_instance)区间。
Lab2 EXTENDIBLE HASH INDEX
第二个Lab是为储存引擎实现一个索引。索引负责快速数据检索,无需搜索数据库表中的每一行,为快速随机查找和高效访问有序记录提供基础。
技术点
- 使用可扩展哈希表为底层数据结构为储存引擎实现多级索引与可扩展。
- 使用动态散列(Dynamic Hashing)技术完成扩展容量时对桶容量和目录的容量,性能开销小。
- 使用节点粒度的锁保证在多线程并发访问下的线程安全性。
实现细节
Bustbub中通过可扩展哈希的数据索引过程:
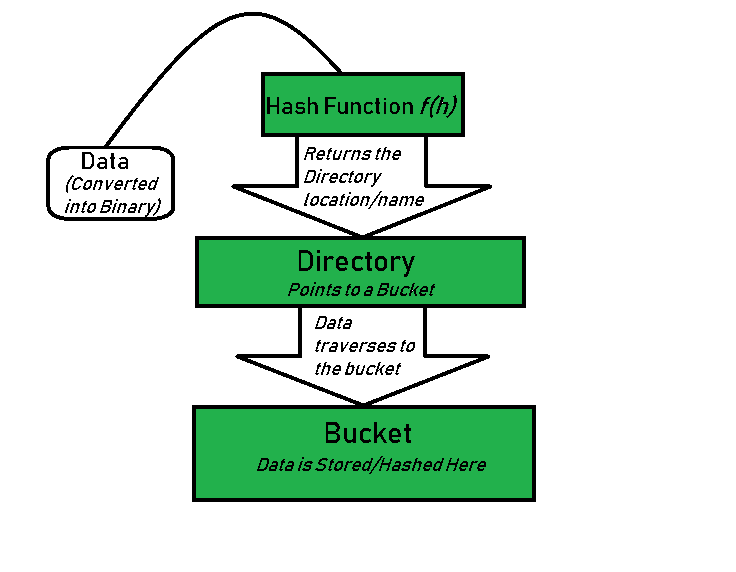
- key——>DirectoryIndex:DirectoryIndex = Hash(key) & GLOBAL_DEPTH_MASK
- DirectoryIndex——>Bucket
HashTableDirectoryPage实现(目录页):
- 目录页单独占用buffer pool中的一个page,目录页中维护目录页的page_id,global depth和存放桶page_id的数组bucket_page_ids以及存放桶local depth的数组local_depths
- 在增加bucket之后如果需要扩充目录页,需要增加global depth,此时目录页不仅要更新global depth的值,还需要重新完成local_depths和bucket的初始化,
- 在合并或删除bucket时,目录页通过遍历local depth数组,判断是否所有局部深度都小于全局深度,如果是则可以收缩全局深度。
HashTableBucketPage实现(桶页):
- Bucket中以K-V键值对的形式存储数据,数据被存储在MappingType中。
- 桶中的可读和占用判断采用两个bitmap,occupied和readable判断和设置,这两个bitmap都是char[]数组,一个char有8位,所以readable和occupied的长度是array的1/8。比如如果要查询array的第10个元素是否有数据,则需要查看readable数组第10/8=1个元素的第10%8=2位元素。即(readable[1] >> 2) & 0x01的值。bitmap的存储方式有效节省了存储成本。
- 对于桶的遍历,occupied_[i]==false之后的数据就可以不用遍历了,如果要查看某一位是否有数据,只需要查看readable[i]的值,为false即为第i位没有存储,有效节省遍历成本。
- 对于桶中插入K-V对,需要先判定桶是否满,如果不满,则查询桶中是否有当前插入key的K-V对,如果没有则可以继续插入(因为BusTub设置了key的唯一性),之后遍历桶查找空闲位插入,并置该位的readable和occupied都为1。
- 对于桶中特定key的移除,需要置该位readable为0并置该位occupied为1,避免出现移除后不连续的存储带来的遍历出错。
ExtendibleHashTable实现(哈希表结构):
- ExtendibleHashTable完成了对哈希表的增删改查操作。
- 对于由key值查找value,第一步先获取目录页,然后根据目录页调用KeyToPageId,由key获取具体是否有该Page存在,若存在则返回该Page对应的bucket_id,由bucket_id从缓冲池中取得实际的bucket page,完成之后还需要对这个bucket page进行Unpin操作,表明进程已经完成了对该页的操作。
- 对于插入操作,第一步先获取目录页,然后根据目录页调用KeyToPageId,由key获取到要插入的桶位置,尝试插入并检查是否桶溢出(overflow),如果此时桶数组未满,则可以直接插入,如果已经满了,则分两种情况讨论溢出:①如果溢出Bucket的局部深度等于全局深度,则需要进行目录页的扩展,以及桶分裂,然后将全局深度和局部深度值加 1。并分配适当的指针;②如果局部深度小于全局深度,则只进行桶分裂。然后仅将局部深度值增加 1。并且,分配适当的指针;最后同样要对这个bucket page进行Unpin操作,表明进程已经完成了对该页的操作。
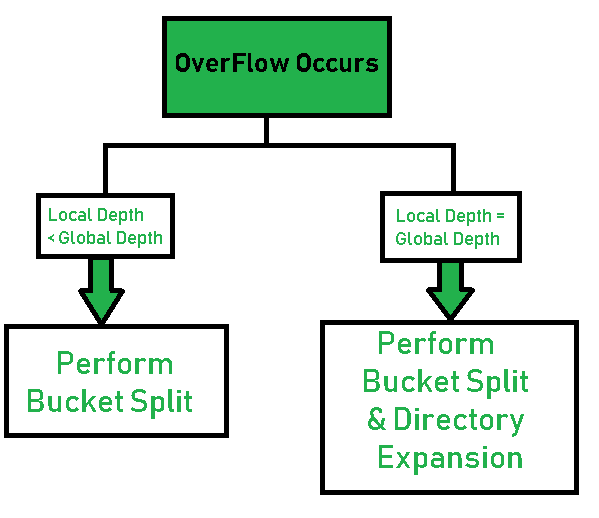
- 对于插入操作提及的桶分裂,在BusTub中,对于分裂的桶,会获取这个桶里面的所有元素以及元素的数量,然后构造(申请一个新的)镜像页,把镜像页的基本信息写入到目录页里面,比如说页的局部深度以及ID等等。
- 对于给定key的删除,BusTub在目录页中通过hash找到这个key应该位于哪一页,再交由下层去该页中查找数据value并删除,删除后,判断该页是否为空,如果为空,则需要将该页merge到相应页中(通过local_depth决定)。
- 对于删除之后的merge操作,BusTub根据删除项的key获得桶位置,如果获取的桶位置没有存放值,且该位置的local depth与global depth相同,则将该空页与其他页进行合并。根据bucket_id^(0x1 << (bucket_local_depth - 1))取得其他页的基址,之后重新分配其他页的page_id,磁盘上删除该空页,就完成了merge操作。
节点粒度的锁:
- 对于查询(getValue)全局加读锁。
- 对于插入(Insert),删除(Remove)全局加写锁。
Lab3 QUERY EXECUTION
第三个Lab是为储存引擎实现查询执行。查询执行负责获取查询计划节点并执行它们的执行器,这部分执行器包括:顺序扫描(Sequential Scan)、插入(Insert)、更新(Update)、删除(Delete)、嵌套循环连接算法(Nested Loop Join)、哈希连接算法(Hash Join)、聚合(Aggregation)、限制(Limit)、唯一(Distinct)。Bustub中采用的是迭代模型(火山模型)实现,将关系代数中每一种操作抽象为一个 Operator,将整个 SQL 构建成一个 Operator 树,查询树自顶向下地调用next()接口,数据则自底向上的被拉取处理。
技术点
- 使用火山模型实现了查询计划,将关系代数中的每一种操作抽象为一个Operator,将整个 SQL 构建成一个 Operator 树。
- 采取工厂模式调用每个执行器,通过工厂模式类将输入查询计划转换为查询执行器,并执行它直到收集到所有结果。
- 对于连接算法,相较传统的嵌套循环连接算法,提供了HashJoin的方式。
- 对于聚合函数的实现,采用了HashAggregate的方式。
实现细节
数据结构
- Value:从最小的类开始。Value可以理解为单元格,并且提供了一些比较和运算的函数。
- Tuple:可以理解为一行。其中的data字段存储了Value,使用GetValue()即可获得。虽然tuple中有rid字段,但是在插入tuple操作中没有对其进行修改,而且也备注了该字段只在指向TableHeap时有用,所以不能把它当成tuple所在的RID。
- TablePage:继承于Page类,是表的存储单元。提供了对页中Tuple的操作。
- TableHeap:可以理解为一个表的物理表示,对应TablePage的双向链表。提供了对表中Tuple增删改查的操作。
- TableHeap的迭代器,由于其运算符已经重载,所以可以当成Tuple的指针来使用。
- RID:RID对应物理表页ID及在页中槽的位置,一般记录一个tuple的物理位置。
- Column:表格一列的列头信息,包含类型、名称等。
- Schema:表格的所有列头,主要包含一个Column的数组。
- Index:表格的索引信息,每个索引提供tuple到RID的对应关系,依靠Lab2的ExtendibleHashTable实现。
- CataLog:一个数据库的全部表格信息的索引,提供了对表格的操作。成员变量主要包括:TableInfo的表,每个TableInfo包括一个表格的ID、Schema、TableHeap;IndexInfo的表,即每个表格的索引信息。
- AbstractExpression:对where语句(其实不止where语句中用到)进行拆分,形成一个树,其中的每一个节点就对应一个AbstractExpression类,该抽象类包括其子节点以及返回类型,还有其他有用的方法。
- AbstractExecutor:executor的实现。主要的函数是Next(),以tuple为单位执行。
- ExecutorContext:一个executor执行的背景信息,包括Executor所在数据库的Catalog,也就是包含该数据库的信息。
- ExecutionEngine:创建并执行executor,输入AbstractPlanNode和ExecutorContext,不断执行AbstractExecutor的Next(),输出结果Tuple(如果需要输出)。
存储模型:
- 物理模型从小到大分别由类Value、Tuple、TablePage、TableHeap存储。
- 逻辑模型由从小到大Column、Schema存储
数据库到表到列的映射方式:
- 通过构造TableHeap并分配对应的schema和一个新的table_oid组成一个Meta元数据(包含schema、table_name、table heap、table_oid),返回指向元数据的指针,实现DBMS将新表添加到数据库并可以使用名称或内部对象标识符 (table_oid) 检索它们。
- Catlog中的tables_是一个unordered_map,其key为table_oid,value是表的所有信息TableInfo,通过这样的映射方式,再构造一个<表名,table_oid>,就可以完成从表名到table_oid的映射。
- 表名到表中所有列(index)的映射是通过一个构造方式为<表名,<列名,列id>>的unordered_map(table name -> index names -> index identifiers)
顺序查询(SeqScan):
- 顺序查询的思路非常简单。就是从头开始遍历整个表的所有tuple,在
Next函数中判断迭代器所指的 tuple 是否满足查询条件并递增迭代器,找到满足要求的tuple。BusTub提供了Evaluate()函数,可以用来判断一个元组是否满足Predicate中的表达式,它会返回一个Value对象,并将tuple中的满足要求的value和outSchema组合成新的tuple存入result就可以实现顺序执行。
- 顺序查询的思路非常简单。就是从头开始遍历整个表的所有tuple,在
插入(Insert):
需要做两件事,一是把tuple插入到table中,二是更新tale的所有索引
对于插入的tuple也分为两种:
一种是原生的tuple,列的值放在InsertPlanNode之中,如:
1
Insert Into test_table Values ()...
另一种是从其他table中复制一个tuple插入,如:
1
Insert Into test_table Select somecols From Another_Table Where .
BusTub中的InsertPlanNode提供了IsRawInsert方法判断是否是原生插入,对于原生插入的数据,我们得到这部分raw data之后构造一个tuple插入到表中;对于非原生插入的数据,需要从其他table中复制一个tuple插入,此时需要执行其下个子树的plan,递归执行后得到实际的values,插入到table heap中。
更新(Update):
- 更新操作是在表中修改一个元素并在索引中进行更新,这个执行器的子执行器会提供需要修改的元组的RID信息,同时更新操作总是从子执行器(查询计划的子结点)中获得要操作的元组信息,即Update一定会跟一个Select操作(虽然SQL里面没有,但是数据库系统实际执行过程中就是要先Select出所有的元组然后再Update的)。
- 同时Bustub中提供了GenerateUpdatedTuple来根据查询计划中的Schema生成修改后的元组,并在TableHeap里进行表的修改。GenerateUpdatedTuple会判断更新的类型是Add还是Set,以此来构造Value更新对应的表。
删除(Delete):
- 删除类似于插入,同样要完成两件事,一是在table中删除tuple,二是删除table中对应的索引。
- 删除tuple只需要调用MarkDelete方法就可以删除,所有的删除都会在事务提交的时候被应用。
- 删除索引需要调用index_info->index_->DeleteEntry(index_key, *rid, exec_ctx_->GetTransaction());
嵌套循环连接算法(Nested Loop Join):
- Nested Loop Join的基本实现思想是通过一个双重循环扫描两个table,把符合过滤条件的两个Tuple合并
- BusTub提供了EvaluateJoin方法返回两个table连接后过滤的值。
- BustTub通过tuple_idx_的值判断当前是左连接还是右连接。
哈希连接(Hash Join)
- 哈希连接的基本思路是先把一张小表加载到内存哈希表里,然后遍历大表的数据,逐行去哈希表中匹配符合条件的数据。
- HashJoinExecutor在Init中会先将第一个子执行器的Tuple做MakeKey和MakeValue并插入哈希表(使用构造的hash function),之后在Next中遍历第二个子执行器,如果Tuple做MakeKey后这个key在哈希表里,说明满足连接条件,加入结果集。
聚合(Aggregation):
- 聚合执行器内部维护了一个哈希表 SimpleAggregationHashTable 以及哈希表迭代器 aht_iterator_,将键值对插入哈希表的时候会立刻更新聚合结果,最终的查询结果也从该哈希表获取。
- 在Init()中首先对group by的结果进行哈希,将值插入到哈希表SimpleAggregationHashTable 中,之后根据前面使用的聚合函数在内存中维护对应的列表(比如select后面有两个聚合函数,那么在内存中就会维护两个对应的数据)。
- 在Next()中通过使用SimpleAggregationHashTable的迭代器访问对应的结果,通过plan_->GetHaving()->EvaluateAggregate判断tuple是否符合条件。根据output_scheme顺序获取Value,最后根据Value构建Tuple返回结果集。
不同(Distinct):
- Distinct的实现方式与哈希连接和聚合的方式类似。
- 在Init()中将执行器中的结果进行哈希,根据key插入到哈希表,如果表中对应key的条目为0,则插入。
- 在Next()中根据哈希表中的条目构造结果集返回。
限制(Limit):
- Limit的实现比较简单,只需要关心需要返回的条目个数,返回对应结果集。
Lab4 CONCURRENCY CONTROL
第三个Lab是为储存引擎实现并发控制系统。基本思路是实现一个锁管理器,然后用它来支持并发查询执行。锁管理器负责跟踪向事务发出的元组级锁,并支持基于隔离级别适当授予和释放的共享锁和排他锁。
技术点
- 使用Wound-Wait算法实现死锁预防算法,通过杀死年轻事务,等待老事务的方式预防死锁发生。
- 使用悲观的两阶段封锁并发控制协议实现了常见的三种隔离级别READ_UNCOMMITED、READ_COMMITTED 和 REPEATABLE_READ。
实现细节
数据结构:
- Transaction:采用2PL锁协议的事务状态,GROWING -> SHRINKING -> COMMITTED ABORTED。
- IsolationLevel:BusTub中实现了三种常见隔离级别,READ_UNCOMMITED、READ_COMMITTED 和 REPEATABLE_READ。
- AbortReason:BusTub对于回滚的类型,提供了五种类型: LOCK_ON_SHRINKING,UNLOCK_ON_SHRINKING,UPGRADE_CONFLICT, DEADLOCK,LOCKSHARED_ON_READ_UNCOMMITTED。
- LockRequestQueue锁请求队列: 每一个tuple对应的RID都可以有一个LockRequestQueue用来维护对其加锁的请求。LockRequestQueue中有类型为std::condition_variable的变量对请求阻塞(wait())或唤醒(notify_one()/notify_all())。
- lock_table:lock_table用来维护锁请求队列。
上锁(包括共享锁与独占锁):
- 所有的上锁函数在上锁前都进行检验:
- 检查当前事务状态是否为Shrinking,如果是,此时上锁不合法,将事务回滚,返回false。
- 检查当前事务状态是否为Abort, 加锁失败,返回false。
- 如果是RU隔离级别请求S锁, 同样应该回滚事务, 这是因为RU的实现方式就是无锁读, 这样就能读到脏数据了, 如果上了S锁, RU将无法读到脏数据。
- 检查是否已经上过同级或更高级的锁了, 如果是, 返回true。
- 上锁前需要先从lock_table中获取锁请求队列。
- 不同隔离级别的处理:
- READ_UNCOMMITED:只有在需要时上独占锁,如果上共享锁,不合法。
- READ_COMMITTED:要解决脏读的问题,因此读时上共享锁,读完解读锁。
- REPEATABLE_READ:同一事务读两次数据的中途不想被其他事务的写干扰,采用二段封锁协议(2PL)了:事务分为两个阶段(不考虑commit/abort),上锁阶段(GROWING)只上锁,解锁阶段(SHINKING)只解锁。这样,第二次读取时,前一次读取的读锁一定还在,避免了中途被修改。
- 上完锁之后在对应锁的资源集中置入rid。
- 所有的上锁函数在上锁前都进行检验:
锁升级(共享锁升级为独占锁):
- 由于加独占锁需要保证当前没有共享锁,那么如果队列中有两个更新锁的请求,就会互相等待对方解读锁。因此,为了判断是否出现这种情况,在队列中维护标志变量upgrading_,不允许队列中出现两个更新锁的请求。将队列中的读锁请求改为写锁,循环判断是否满足加更新写锁条件(当前没有写锁,且只有唯一一个该读锁)。
- 具体的实现需要从请求队列中得到加锁的事务,从共享锁的资源集释放原先的共享锁,之后更新事务的锁状态为独占锁,同时在独占锁的资源集中置入rid。
解锁:
- 在请求队列和锁的资源集中删除对应的请求(不存在锁请求就return false), 并设置事务状态为Shrinking
- 用条件变量中的notify_all()方法唤醒其他请求,告知可以尝试加锁。
Wound-Wait:
- Wound-Wait的核心思想是如果发现当前持有锁的事务比自己更老,就等待;否则abort掉当前持有锁的事务,自己上锁。(这只是两个事务分别想上一个X锁的情况)
- BusTub中根据事务的id大小判断新老事务,新事务的id较大,如果请求上锁的事务id大于当前事务的id,那么该请求上锁的事务为新事务,应该等待。否则杀死当前事务,解锁,自己上锁。