SQL 是声明性的,所以查询只告诉DBMS需要计算什么,而不是如何计算。
所以DBMS需要将SQL语句转换为可执行的查询计划,但是在查询计划中有不同的方法来执行每个操作符,并且这些计划之间的性能会有所不同。
DBMS优化器的工作是为任何给定查询选择最佳计划。
查询优化有两种高级策略
heuristics 启发式
基于成本的搜索 选择最低成本的计划
查询优化是构建数据库管理系统中最困难的部分。一些系统试图应用机器学习来提高优化器的准确性和效率,但目前没有大型数据库管理系统部署基于这种技术的优化器。
关系代数等价
如果两个关系代数表达式生成相同的元组集,则它们是等价的。
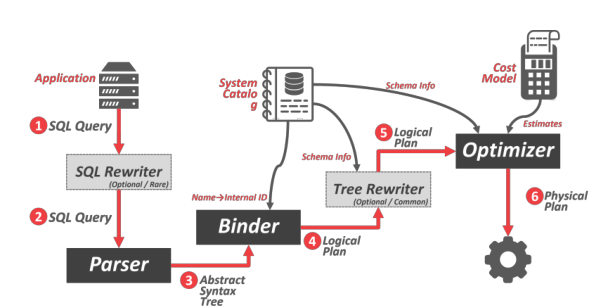
应用程序连接到数据库系统并发送SQL查询,该查询可以重写为不同的格式。SQL字符串被解析为组成语法树的标记。绑定器通过查阅系统目录将语法树中的命名对象转换为内部标识符。绑定器发出一个逻辑计划,可以将该计划提供给树重写器,以获得额外的模式信息。逻辑计划被提供给优化器,优化器选择最有效的过程来执行计划。
这种转换逻辑计划的底层关系代数表示的技术称为查询重写。
逻辑查询优化(Logical Query Optimization)
- 尽早执行过滤器
- 重新排序谓词,以便DBMS首先应用最具选择性的谓词
- 分解复杂谓词并向下推(拆分连接谓词)。
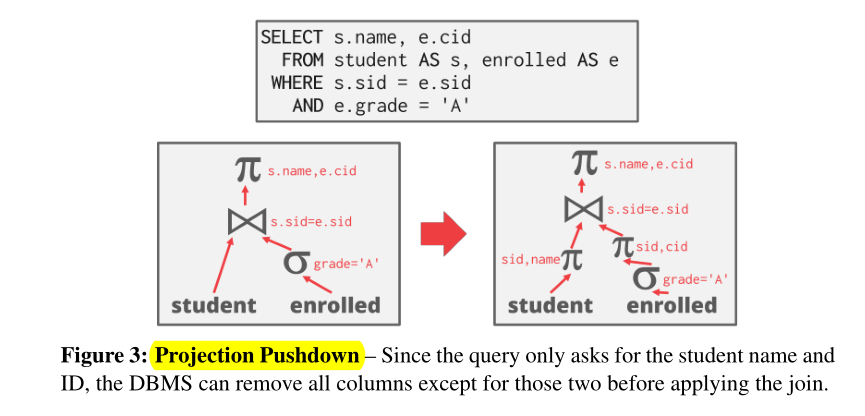
投影下推(Project Pushdown)
- 尽早执行投影以创建较小的元组并减少中间结果(投影下推)。
删除不可能或不必要的谓词
DBMS可以使用的另一个优化是删除不可能或不必要的谓词。在这种优化中,DBMS避免了对谓词的评估,这些谓词的结果在表中的每个元组中都不会改变。绕过这些谓词可以降低计算成本

合并谓词

优化嵌套子查询
共有两种方法
- 展平查询语句

- 分解嵌套查询并将结果存储到临时表中

Cost Estimations
DBMS使用成本模型(cost models)来估计执行计划的成本。这些模型评估查询的等效计划,以帮助DBMS选择最佳计划。
成本估计需要考虑以下四个方面。
- CPU:成本小,但难以估计。
- 磁盘I/O(Disk I/O):blocks传输的数量。
- 内存(Memory):使用的DRAM数量。
- 网络(Networks):发送的消息数。
对于每一个关系R,DBMS维护这么些数据:

optimizer可以通过上述维护的数据得到selection cardinality(选择基数) SC(A,R)

注意,谓词的选择性等同于该谓词的概率。这允许在许多选择性计算中应用概率规则。这在处理复杂谓词时特别有用。例如,如果我们假设一个连接中涉及的多个谓词是独立的,我们可以计算连接的总选择性,作为单个谓词选择性的乘积。
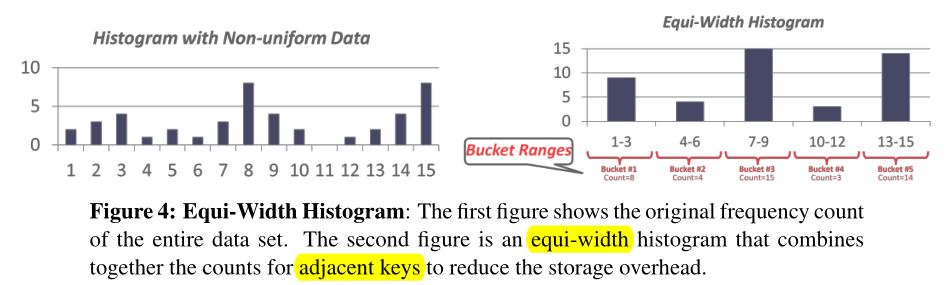
直方图(Histograms)
真实数据往往是扭曲的,很难做出假设。然而,存储数据集的每一个值都很昂贵。减少内存使用量的一种方法是将数据存储在直方图中以将值分组。
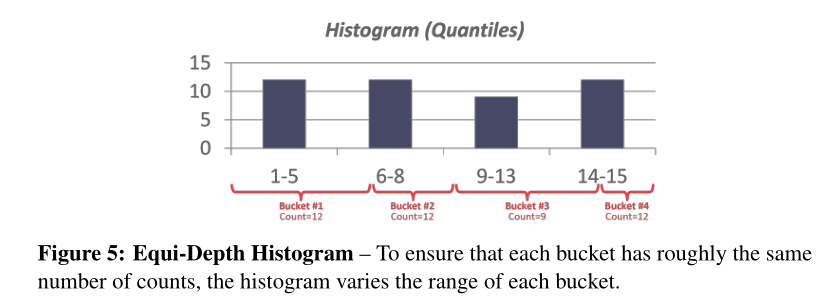
为了确保每个桶的计数数量大致相同,直方图会改变每个桶的范围。
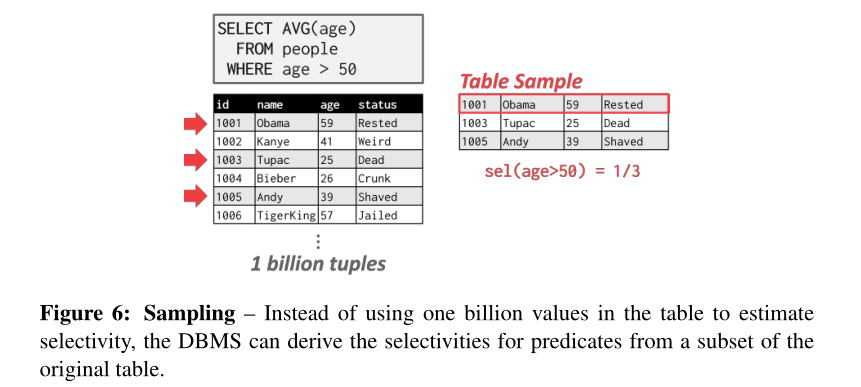
抽样(Sampling)
DBMS可以使用采样将谓词应用于具有类似分布的表的较小副本(见图6)。只要基础表的更改量超过某个阈值(例如元组的10%),DBMS就会更新样本。
枚举计划(Plan Enumeration)
在执行基于规则的重写之后,DBMS将枚举查询的不同计划并估计其成本。然后,在耗尽所有计划或超时后,它为查询选择最佳计划。
共有两种方法:
单关系查询计划(Single-Relation Query Plans)
- 选择最佳access method(即顺序扫描、二进制搜索、索引扫描等)
- 大多数新数据库系统只是使用启发式方法,而不是复杂的成本模型来选择访问方法。对于OLTP查询,这尤其容易,因为它们是可搜索的(可搜索参数),这意味着存在可以为查询选择的最佳索引。这也可以通过简单的启发式实现
多关系查询计划(Multi-Relation Query Plans)
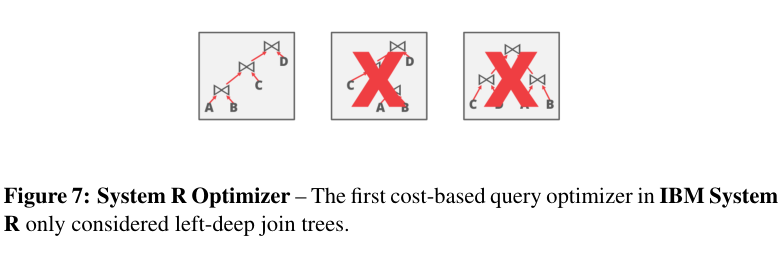
- IBM System R只考虑左深连接树
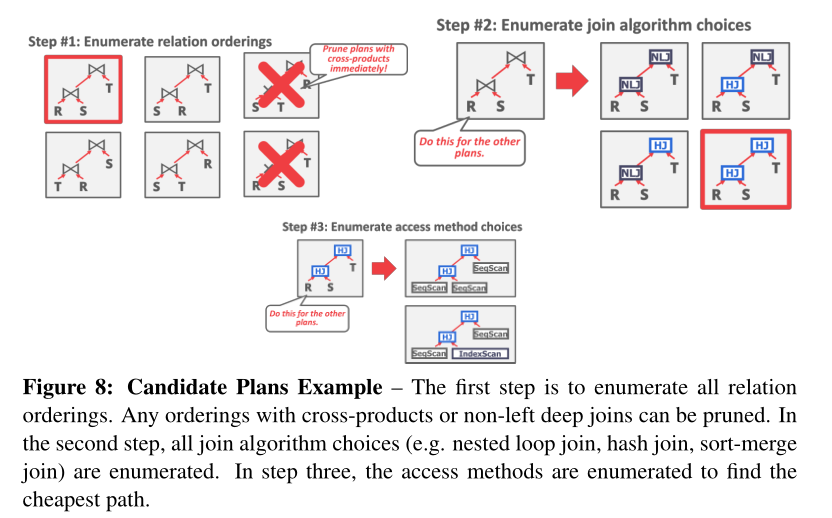
- 为了制定一个优化的查询计划,DBMS首先会进行排序枚举,之后是连接枚举,之后再是access method枚举【第一步是枚举所有关系排序。可以修剪任何具有叉积或非左深联接的排序。在第二步中,枚举所有连接算法选择(例如嵌套循环连接、哈希连接、排序合并连接)。在第三步中,枚举访问方法以找到最便宜的路径。 】
- IBM System R只考虑左深连接树