注:Intra前缀是在……之内的意思,Inter前缀是在……之间的意思
Paraller execution
DBMS支持两种类型的并行:查询间并行【inter-query parallelism】和查询内并行【intra-query parallelism】
Parallel vs Distributed
并行数据库中资源或者节点再物理上彼此接近。DBMS中的节点通过高速互连进行通信。资源之间的通信不仅快速,而且便宜可靠。
分布式数据库中资源可能彼此远离,资源通过公网使用较慢的互联进行通信。节点之间的通信成本比较高,故障不能忽略。
Inter-Query Parallelism【查询间并行】
DBMS同时执行不同的查询。由于多个工作进程同时运行请求,因此总体性能得到了提高。这增加了吞吐量并减少了延迟。
如果查询是只读的,那么并没有影响。如果在查询的同时更新数据库,则会出现冲突
Intra-Query Parallelism【查询内并行】
在查询内并行是指DBMS并行执行单个查询的操作,这减少了长时间运行查询的延迟。
可以将查询内并行考虑为一个生产者/消费者问题。
每个关系运算符都有并行算法,DBMS可以让多个线程访问集中式数据结构,也可以使用分区来划分工作
查询内并行包括:1.intra-operator 2. inter-operator 3.bushy
Intra-Operator Parallelism (Horizontal)
在intra-operator parallelism中,一个查询计划被分解为独立的片段【fragment】,这些片段对不同(不相交)的数据子集执行相同的功能。
DBMS会在查询计划中插入一个exchange operator来合并子运算的结果,exchange operator可以防止DBMS执行其(exchange operator)上的运算符,直到exchange operator从其子节点中接受到所有的数据。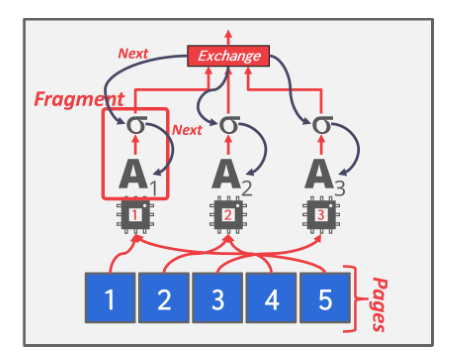
有三种不同类型的exchange operator:
- Gather:将多个workers的结果合并到单个输出流中
- Repartition:对多个输出流中重新分区为多个输入流
- Distribute:将单个输入流拆分为多个输出流
Inter-Operator Parallelism (Vertical)
又称流水线并行(pipelined),这种方法广泛应用于流处理系统中,流处理系统是通过输入元组流连续执行查询的系统。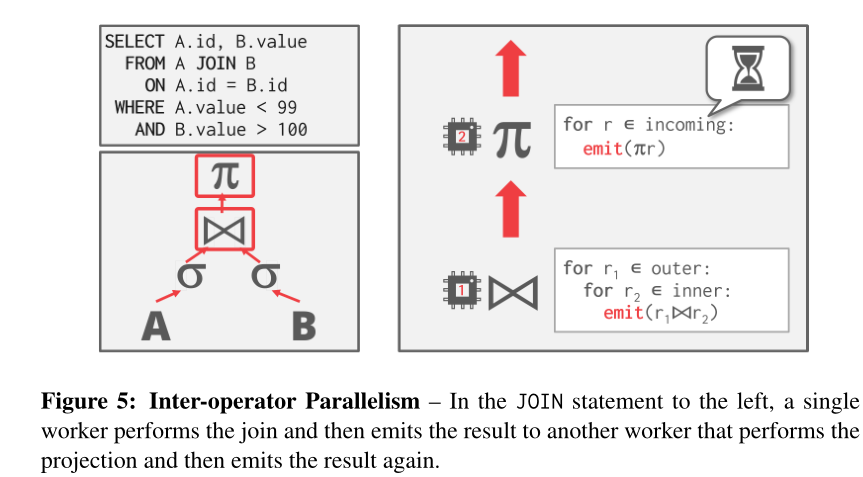
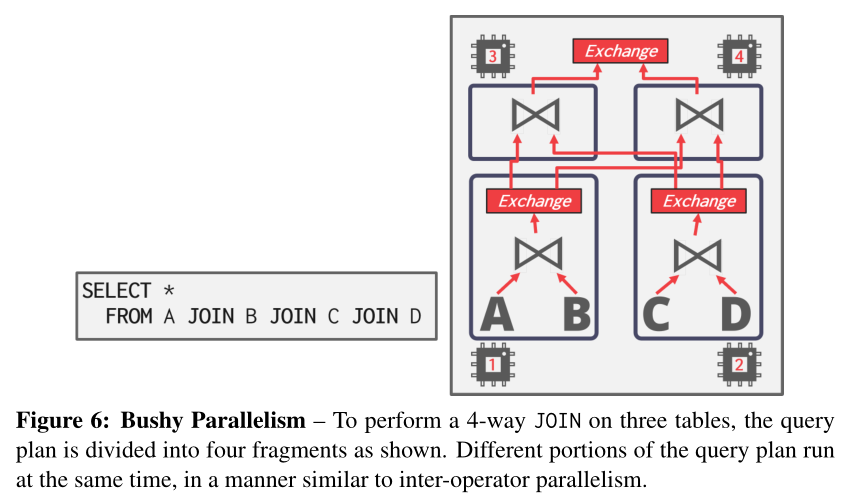
Bushy Parallelism
Process Models
DBMS可以采用三种不同的进程模型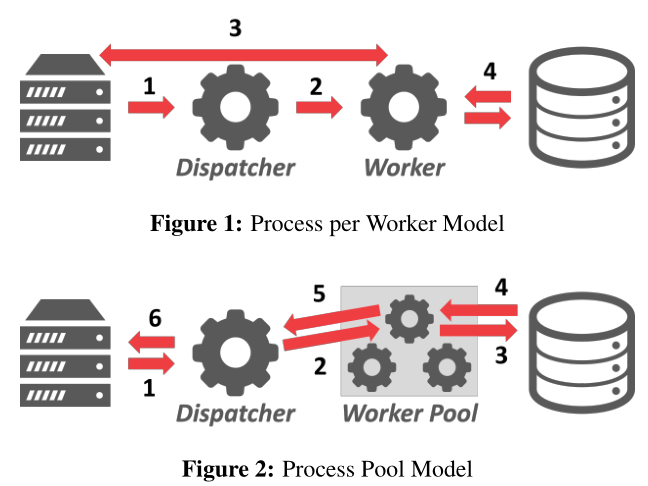
Process per worker
每一个worker都是一个单独的操作系统进程,因此这种模式依赖OS调度。
应用程序发送请求并打开与数据库系统的连接。一些调度器接收到该请求,并分配一个worker进程来处理该连接。应用程序现在直接与负责执行查询所需请求的worker通信。
这样的优点是进程不会破坏整个系统,因为每个worker都在其操作系统进程的上下文中进行。
这样的缺点是当多个不同的worker对同一个page进行大量复制的时候,最大化内存使用率的方案应该要采用全局数据结构来使用共享内存,以便不同进程中运行的worker可以共享这些数据结构。
Process pool
进程池模型是worker模型的扩展。
与对每个连接请求fork进程不同,worker会被保存在一个pool中,并在查询到达的时候由调度程序选择。
由于进程们都在pool中,因此进程们可以彼此共享查询。
与每个进程一个worker一样,process pool也依赖于OS调度程序和共享内存。
这样的缺点是难以进行CPU缓存,因为不能保证在查询之间使用相同的进程
Thread per Worker

DBMS完全控制任务和线程,它可以管理自己的调度。多线程模型可以使用调度线程,也可以不使用调度线程。
使用多线程架构提供了某些优势。首先,每个上下文切换的开销较小。此外,不必维护共享模型。
然而,Thread per Worker并不一定意味着DBMS支持查询内并行