2021年Linux内核分析笔记,仅供参考。
LKA笔记
NASM编程基础
NASM变量声明
初始化数据分配存储空间
初始化数据存储分配语句的语法是:
1
[variable-name]define-directiveinitial-value [,initial-value]...
变量名是每个存储空间的标识符。汇编器在数据段中定义的每一个变量名的偏移值。
有五种基本形式定义指令:
Directive Purpose Storage Space DB Define Byte allocates 1 byte DW Define Word allocates 2 bytes DD Define Doubleword allocates 4 bytes DQ Define Quadword allocates 8 bytes DT Define Ten Bytes allocates 10 bytes 以下是一些例子,使用define指令:
1
2
3
4
5
6choice DB 'y'
number DW 12345
neg_number DW -12345
big_number DQ 123456789
real_number1 DD 1.234
real_number2 DQ 123.456请注意:
- 每个字节的字符以十六进制的ASCII值存储。
- 每个十进制值会自动转换为十六进制数16位二进制存储
- 处理器使用小尾数字节顺序
- 负数转换为2的补码表示
- 短的和长的浮点数使用32位或64位分别表示
寄存器
处理器寄存器
IA-32架构中有10个32位和6个16位处理器寄存器。 寄存器分为三类 -
- General registers,
- 控制寄存器,和
- 段寄存器。
一般登记册进一步分为以下几组 -
- 数据寄存器,
- 指针寄存器,和
- 索引寄存器。
数据寄存器
四个32位数据寄存器用于算术,逻辑和其他操作。 这些32位寄存器可以三种方式使用 -
- 作为完整的32位数据寄存器:EAX,EBX,ECX,EDX。
- 32位寄存器的下半部分可用作4个16位数据寄存器:AX,BX,CX和DX。
- 上述四个16位寄存器的低半部分和高半部分可用作8个8位数据寄存器:AH,AL,BH,BL,CH,CL,DH和DL。
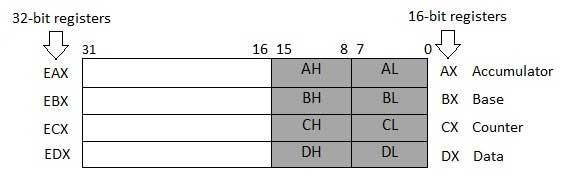
其中一些数据寄存器在算术运算中具有特定用途。
AX is the primary accumulator ; 它用于输入/输出和大多数算术指令。 例如,在乘法运算中,根据操作数的大小,一个操作数存储在EAX或AX或AL寄存器中。
BX is known as the base register ,因为它可以用于索引寻址。
CX is known as the count register ,因为ECX,CX寄存器在迭代操作中存储循环计数。
DX is known as the data register 。 它也用于输入/输出操作。 它还与AX寄存器以及DX一起用于涉及大值的乘法和除法运算。
高位 H 和低位 L:AH、BH、CH、DH、AL、BL、CL、DL
四种 16 位寄存器都能被拆分成高 8 位和低 8 位,也就是 AH、BH、CH、DH 和 AL、BL、CL、DL
这 8 个寄存器并不是新的寄存器,而是取对应 16 位寄存器的部分内容而已,以 AX 的实际存储情形举例

32位 & 64位:EAX、EBX、ECX、EDX、RAX、RBX、RCX、RDX
同时 NASM 也支持我们编写 32 位甚至 64 位的通用寄存器大小,分别是 EAX、EBX、ECX、EDX 和 RAX、RBX、RCX、RDX
例如原来的 AX 即为 EAX 的低 16 位如下

段寄存器
我们来介绍段寄存器,因为后面其他寄存器很多都需要与段寄存器共同使用。NASM 定义的段寄存器有 4+2 种(80386 后多出后面两种,提供更多选择)
CS 指令段寄存器 (Code)
用于保存当前执行程序的指令段(code segment)的起始地址,相当于 section .text 的地址
DS 数据段寄存器 (Data)
用于保存当前执行程序的数据段(data segment)的起始地址,相当于 section .data 的地址
SS 栈寄存器 (Stack)
用于保存当前栈空间(Stack)的基址,与 SP(偏移量) 相加 -> SS:SP 可找到当前栈顶地址
ES 额外段寄存器 (Extra)
常用于字符串操作的内存寻址基址,与变址寄存器 DI 共用
FS、GS 指令段寄存器
80386 额外定义的段寄存器,提供程序员更多的段地址选择
指针寄存器
指针寄存器是32位EIP,ESP和EBP寄存器以及相应的16位右部分IP,SP和BP。 指针寄存器分为三类 -
- Instruction Pointer (IP) - 16位IP寄存器存储下一条要执行的指令的偏移地址。 与CS寄存器相关联的IP(作为CS:IP)给出代码段中当前指令的完整地址。
- Stack Pointer (SP) - 16位SP寄存器提供程序堆栈中的偏移值。 与SS寄存器(SS:SP)相关联的SP指的是程序堆栈内的数据或地址的当前位置。
- Base Pointer (BP) - 16位BP寄存器主要用于引用传递给子程序的参数变量。 SS寄存器中的地址与BP中的偏移量组合以获得参数的位置。 BP也可以与DI和SI组合作为特殊寻址的基址寄存器。
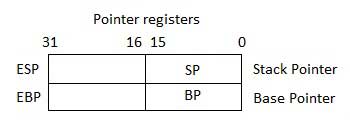
指针寄存器:IP、SP、BP
有了前面的段寄存器保存不同区块(section 或称为段 segment),我们还有三个寄存器作为块中指针(用来保存偏移量 offset)
IP 指令指针 (Instruction Pointer)
与 CS 共用,可透过 CS:IP 寻到当前程序执行到的地址
SP 栈指针 (Stack Pointer)
与 SS 共用,可透过 SS:SP 找到当前栈顶地址
BP 参数指针 (Base Pointer)
与 SS 共用,可透过 SS:BP 找到当前栈底地址
索引寄存器
32位索引寄存器,ESI和EDI,以及它们最右边的16位部分。 SI和DI用于索引寻址,有时用于加法和减法。 有两组索引指针 -
- Source Index (SI) - 用作字符串操作的源索引。
- Destination Index (DI) - 用作字符串操作的目标索引。

控制寄存器
32位指令指针寄存器和32位标志寄存器组合被认为是控制寄存器。
许多指令涉及比较和数学计算,并且更改标志的状态,并且一些其他条件指令测试这些状态标志的值以将控制流程带到其他位置。
公共标志位是:
- Overflow Flag (OF) - 表示在带符号算术运算后数据的高位(最左位)溢出。
- Direction Flag (DF) - 它确定移动或比较字符串数据的左或右方向。 当DF值为0时,字符串操作采用从左到右的方向,当值设置为1时,字符串操作采用从右到左的方向。
- Interrupt Flag (IF) - 它确定是否要忽略或处理键盘输入等外部中断。 它在值为0时禁用外部中断,在设置为1时启用中断。
- Trap Flag (TF) - 它允许以单步模式设置处理器的操作。 我们使用的DEBUG程序设置了陷阱标志,因此我们可以一次执行一条指令。
- Sign Flag (SF) - 它显示算术运算结果的符号。 根据算术运算后的数据项的符号设置该标志。 符号由最左边的位的高位表示。 正结果将SF的值清除为0,否定结果将其设置为1。
- Zero Flag (ZF) - 它表示算术或比较运算的结果。 非零结果将零标志清除为0,零结果将其设置为1。
- Auxiliary Carry Flag (AF) - 它包含算术运算后从第3位到第4位的进位; 用于专业算术。 当1字节算术运算导致从第3位进位到第4位时,AF置位。
- Parity Flag (PF) - 它表示从算术运算获得的结果中的1位总数。 偶数个1位将奇偶校验标志清除为0,奇数个1位将奇偶校验标志设置为1。
- Carry Flag (CF) - 在算术运算后,它包含来自高位(最左边)的0或1的进位。 它还存储shift或rotate操作的最后一位的内容。
下表显示了16位Flags寄存器中标志位的位置:
| 旗: | O | D | I | T | S | Z | A | P | C | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 位号: | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
细分寄存器
段是在程序中定义的用于包含数据,代码和堆栈的特定区域。 主要有三个部分 -
- Code Segment - 它包含要执行的所有指令。 16位代码段寄存器或CS寄存器存储代码段的起始地址。
- Data Segment - 它包含数据,常量和工作区域。 16位数据段寄存器或DS寄存器存储数据段的起始地址。
- Stack Segment - 它包含过程或子例程的数据和返回地址。 它被实现为“堆栈”数据结构。 堆栈段寄存器或SS寄存器存储堆栈的起始地址。
除DS,CS和SS寄存器外,还有其他额外的段寄存器 - ES(额外段),FS和GS,它们提供用于存储数据的附加段。
在汇编编程中,程序需要访问存储器位置。 段内的所有存储器位置都相对于段的起始地址。 段开始于可被16或十六进制10整除的地址。因此,所有这些存储器地址中最右边的十六进制数字是0,通常不存储在段寄存器中。
段寄存器存储段的起始地址。 要获得段内数据或指令的确切位置,需要偏移值(或位移)。 为了引用段中的任何存储器位置,处理器将段寄存器中的段地址与位置的偏移值组合。
内存段
分段存储模型的系统内存划分成独立的段,引用指针位于段寄存器组。每个段是指包含特定类型的数据。一个段被用于包含指令代码,另一个段存储的数据元素,和第三个分部保持程序堆栈。
根据上面的讨论,我们可以指定不同的内存段:
- 数据段 - 它由数据段的和bss段。数据段的用来声明数据元素的存储程序的内存区域。本节不能扩大后的数据元素的声明,并在整个程序中它仍保持不变。
bbs部分是静态内存部分,其中包含的缓冲区进行数据宣布以后在程序。这个缓冲存储器是零填充。
代码段 - 它表示文字部分。这定义的区域在存储器中存储的指令代码。这也是一个固定的区域。
堆 - 此段包含传递给程序的功能和程序内的数据值。
数据(data)段被用于声明初始化的数据或常数。此数据在运行时不会更改。您可以在段中声明各种常量值,文件名或缓冲区大小等。
声明数据段的语法是-
1
section.data
bss 段
在bss段用于声明变量(未初始化变量和静态变量)。声明bss段的语法是
1
section.bss
text段
代码段被用于保持实际的代码。该段必须以全局声明**_start**开头,该声明告诉内核程序从何处开始执行。
声明代码段的语法是-
1
2
3section.text
global _start
_start:
方括号[]的使用

$和$$
$关键字
表示是的当前行,起到标号的作用。其由NASM提供支持,并非CPU原生支持,相当于伪指令。
$属于“隐式地”藏在本行前的标号,也就是当前安排的地址,每一行都有。
例如有如下代码,在此条指令循环:1
labe1: jmp label1
我们可以改写为:
1
jmp $
$$关键字
$$ 代表本节section的起始地址。
例如我们的代码如下:1
section mycode1 ... ...section mycode2 ... ...
我们可以看到这里有2个节,各个节中如果要获取各节的起始地址,则可以在其节代码中用$$获取。
相同的节名,在编译时会自动合并。
section是给我们程序开发人员逻辑上的规划,我们可以把一类代码放在一个节中,这样编译器就是把这个代码放在了一起
Nasm寻址方式
寄存器寻址
在这种寻址方式中,寄存器包含操作数。根据不同的指令,寄存器可能是第一个操作数,第二个操作数或两者兼而有之。
例如,
1
2
3MOV DX, TAX_RATE ; Register in first operand
MOV COUNT, CX ; Register in second operand
MOV EAX, EBX ; Both the operands are in registers随着处理数据寄存器之间不涉及内存,它提供数据的处理速度是最快的。
立即寻址
立即数有一个恒定的值或表达式。当一个指令有两个操作数使用立即寻址,第一个操作数是寄存器或内存中的位置,和第二个操作数是立即数。第一个操作数定义的数据的长度。
1
2
3
4BYTE_VALUE DB 150; A byte value is defined
WORD_VALUE DW 300; A word value is defined
ADD BYTE_VALUE, 65; An immediate operand 65 is added
MOV AX, 45H ; Immediate constant 45H is transferred to AX- 直接存储器寻址
当操作数指定内存寻址模式,直接访问主存储器的数据段,通常是必需的。这种方式处理的数据的处理速度较慢的结果。为了找到确切的位置在内存中的数据,我们需要段的起始地址,这是通常出现在DS寄存器和偏移值。这个偏移值也被称为有效的地址。
在直接寻址方式,是直接指定的偏移值作为指令的一部分,通常由变量名表示。汇编程序计算的偏移值,并维护一个符号表,它存储在程序中使用的所有变量的偏移值。
在直接存储器寻址,其中一个操作数是指一个内存位置和另一个操作数引用一个寄存器。
例如,
1
2ADD BYTE_VALUE, DL ; Adds the register in the memory location
MOV BX, WORD_VALUE ; Operand from the memory is added to register- 直接偏移量寻址
1
2
3
4
5
6
7
8
9
10这种寻址模式使用算术运算符修改一个地址。例如,看看下面的定义来定义数据表:
BYTE_TABLE DB 14, 15, 22, 45 ; Tables of bytes
WORD_TABLE DW 134, 345, 564, 123 ; Tables of words
可以进行以下操作:从存储器到寄存器中的表访问数据:
MOV CL, BYTE_TABLE[2] ; Gets the 3rd element of the BYTE_TABLE
MOV CL, BYTE_TABLE + 2 ; Gets the 3rd element of the BYTE_TABLE
MOV CX, WORD_TABLE[3] ; Gets the 4th element of the WORD_TABLE
MOV CX, WORD_TABLE + 3 ; Gets the 4th element of the WORD_TABLE间接寻址
这种寻址模式利用计算机的能力分部:偏移寻址。一般基寄存器EBX,EBP(BX,BP)和索引寄存器(DI,SI),编码的方括号内的内存引用,用于此目的。
通常用于含有几个元素的类似,数组变量间接寻址。存储在数组的起始地址是EBX寄存器。
下面的代码片段显示了如何访问不同元素的变量。
1
MY_TABLE TIMES 10 DW 0 ; Allocates 10 words (2 bytes) each initialized to 0MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBXMOV [EBX], 110 ; MY_TABLE[0] = 110ADD EBX, 2 ; EBX = EBX +2MOV [EBX], 123 ; MY_TABLE[1] = 123
MOV指令
MOV指令的语法是:
1
MOV destination, source
MOV指令可以具有以下五种形式之一:
1
2
3
4
5MOV register, register
MOV register, immediate
MOV memory, immediate
MOV register, memory
MOV memory, registerMOV操作操作数应该是同样大小
源操作数的值保持不变
系统调用
可以利用Linux系统调用汇编程序。如需要在程序中使用Linux系统调用,请采取以下步骤:
- 把EAX寄存器中的系统调用号。
- 在寄存器存储的参数的系统调用 EBX, ECX等.
- 调用相关的中断 (80h)
- 其结果通常是返回在EAX 寄存器
有6个寄存器存储系统调用的参数。 它们有 EBX, ECX, EDX, ESI, EDI 和 EBP.
这些寄存器采取连续的参数,起始带EBX寄存器。如果有超过六个参数,那么第一个参数的存储位置被存储在EBX寄存器。
下面的代码片段显示了使用系统调用sys_exit:
1 | mov eax,1 ; system call number (sys_exit) |
下面的代码片段显示了使用系统调用sys_write:
1 | mov edx,4 ; |
列出了所有的系统调用 /usr/include/asm/unistd.h , 连同他们的编号(之前把在EAX调用int80H)。
下表显示了一些本教程中使用的系统调用:
| %eax | Name | %ebx | %ecx | %edx | %esx | %edi |
|---|---|---|---|---|---|---|
| 1 | sys_exit | int | - | - | - | - |
| 2 | sys_fork | struct pt_regs | - | - | - | - |
| 3 | sys_read | unsigned int | char * | size_t | - | - |
| 4 | sys_write | unsigned int | const char * | size_t | - | - |
| 5 | sys_open | const char * | int | int | - | - |
| 6 | sys_close | unsigned int | - | - | - | - |
数组
我们已经讨论了用于为变量分配存储的数据定义指令的汇编。变量也可以用一些特定的值被初始化。可以指定初始化值,十六进制,十进制或二进制形式。
例如,我们可以定义一个字变量months 以下方式之一:
1 | MONTHS DW 12 |
数据定义指令也可以被用于定义一个一维数组。让我们定义一个一维数组存储数字。
1 | NUMBERS DW 34, 45, 56, 67, 75, 89 |
上述定义数组声明六个字每个初始化的数字34,45,56,67,75,89。此分配2×6=12个字节的连续的存储器空间。符号地址的第一个数字的号码,以及该第二个数字将号码+2,依此类推。
让我们举了另一个例子。可以定义一个数组大小为8的空间,并初始化所有值为零,如:
1 | INVENTORY DW 0DW 0DW 0DW 0DW 0DW 0DW 0DW 0 |
其中,可以缩写为:
1 | INVENTORY DW 0, 0 , 0 , 0 , 0 , 0 , 0 , 0 |
TIMES指令也可以被用于多个初始化为相同的值。使用TIMES,数组可以被定义为
1 | INVENTORY TIMES 8 DW 0 |
下面的示例演示通过上述概念定义一个3元素数组x,其中存储了三个值:2,3和4。它添加数组中的值并显示的总和9:
1 | section .text |
上面的代码编译和执行时,它会产生以下结果:
1 | 9 |
条件判断
在汇编语言中的条件执行是通过几个循环和分支指令。这些指令可以改变在程序的控制流。有条件的执行过程中观察到两种情况:
| SN | 条件说明 |
|---|---|
| 1 | 无条件跳转 这是通过JMP指令。有条件的执行往往涉及控制权移交给一个指令的地址不遵循当前执行的指令。控制转移可能会执行一组新的指令或向后,以便重新执行相同的步骤。 |
| 2 | 条件跳转 这是由一组跳转指令Ĵ<条件>视条件而定。条件指令控制转移,打破了连续流程,他们这样做是通过改变IP中的偏移值。 |
CMP 指令
CMP指令比较两个操作数。它通常用于在条件执行。该指令基本上减去一个操作数进行比较的操作数是否等于或不从其他。它不干扰源或目的操作数。它是用来为决策的条件跳转指令。
语法
1 | CMP destination, source |
CMP比较两个数字数据字段。目的操作数可以是寄存器或内存中。源操作数可以是一个常数(立即)数据,寄存器或内存。
例子:
1 | CMP DX, 00 ; Compare the DX value with zeroJE L7 ; If yes, then jump to label L7..L7: ... |
CMP往往是用于比较的计数器值是否已经达到了一个循环的时间的数量需要运行。考虑以下典型条件:
1 | INC EDXCMP EDX, 10 ; Compares whether the counter has reached 10JLE LP1 ; If it is less than or equal to 10, then jump to LP1 |
无条件跳转
正如前面提到的,这是在JMP指令执行。有条件的执行往往涉及控制权移交给一个指令的地址不遵循当前执行的指令。控制转移可能会执行一组新的指令或向后,以便重新执行相同的步骤。
语法:
JMP指令立即传送控制流提供了一个标签名称。 JMP指令的语法是:
1 | JMP label |
实例:
下面的代码片段说明JMP指令:
1 | MOV AX, 00; Initializing AX to 0 |
有条件跳转
如果某些指定的条件跳转条件满足时,控制流程转移到目标指令。有多个条件跳转指令,根据条件和数据。
以下是条件跳转指令用于有符号数据用于算术运算:
| Instruction | Description | Flags tested |
|---|---|---|
| JE/JZ | Jump Equal or Jump Zero | ZF |
| JNE/JNZ | Jump not Equal or Jump Not Zero | ZF |
| JG/JNLE | Jump Greater or Jump Not Less/Equal | OF, SF, ZF |
| JGE/JNL | Jump Greater or Jump Not Less | OF, SF |
| JL/JNGE | Jump Less or Jump Not Greater/Equal | OF, SF |
| JLE/JNG | Jump Less/Equal or Jump Not Greater | OF, SF, ZF |
以下是条件跳转指令用于无符号数据用于进行逻辑运算:
| Instruction | Description | Flags tested |
|---|---|---|
| JE/JZ | Jump Equal or Jump Zero | ZF |
| JNE/JNZ | Jump not Equal or Jump Not Zero | ZF |
| JA/JNBE | Jump Above or Jump Not Below/Equal | CF, ZF |
| JAE/JNB | Jump Above/Equal or Jump Not Below | CF |
| JB/JNAE | Jump Below or Jump Not Above/Equal | CF |
| JBE/JNA | Jump Below/Equal or Jump Not Above | AF, CF |
下列条件跳转指令有特殊的用途及检查的标志值:
| Instruction | Description | Flags tested |
|---|---|---|
| JXCZ | Jump if CX is Zero | none |
| JC | Jump If Carry | CF |
| JNC | Jump If No Carry | CF |
| JO | Jump If Overflow | OF |
| JNO | Jump If No Overflow | OF |
| JP/JPE | Jump Parity or Jump Parity Even | PF |
| JNP/JPO | Jump No Parity or Jump Parity Odd | PF |
| JS | Jump Sign (negative value) | SF |
| JNS | Jump No Sign (positive value) | SF |
在J<条件>的指令集的语法:
例如,
1 | CMP AL, BLJE EQUALCMP AL, BHJE EQUALCMP AL, CLJE EQUALNON_EQUAL: ...EQUAL: ... |
保护模式
实模式与保护模式
- 实模式
- 它通过20位地址分段访问1MB地址空间
- 程序可以直接访问BIOS中断和外设
- 硬件层不支持任何内存保护或者多任务处理
- 保护模式
- 硬件为系统软件实现虚拟内存、分页机制、安全的多任务处理的功能支持
- 提供操作系统对应用程序的控制功能:特权级、实模式应用程序兼容、虚拟8086模式
- 寻址方式比较
- 实模式是两个16位逻辑地址(段地址:偏移地址)组合成20位物理地址
- 保护模式寻址中,段基址(Segment Base Address)被放在段描述符(Segment Descriptor)中,GDT(Global Desciptor Table)保存着所有段描述符的信息,段选择子是指向某个段描述符的索引
GDT(Global Desciptor Table)
GDT由来
在实模式中,物理地址遵循这样的计算公式
1
物理地址 = 段值 * 16 + 偏移
其中,段值和偏移都是16位的
但是后来80386有了32位地址线,寻址空间可以达到4GB,一个寄存器就可以寻址4GB空间。所以在【保护模式】中的地址仍然用【段:偏移】这样的形式表示,只不过保护模式下“段”的概念发生了根本性的变化。实模式下,段值还是可以看作是地址的一部分的,段值位XXXXh表示以XXXX0h开始的一段内存。而保护模式下,虽然段值仍然由原来16位的cs、ds等寄存器表示,但此时它仅仅变成了一个索引,这个索引指向一个数据结构的表项,表项中详细定义了起始地址、界限、属性等内容。这个数据结构,就是GDT(也可能是LDT)。GDT中的表项也有一个专门的名字,叫做【描述符】

进入保护模式,我们需要解决两个问题,一是如何获取超过1M以上的内存地址,第二是如何设置不同代码所具有的优先级。我们先看看寻找能力的变化,在实模式下,cpu是16位的,寄存器16位,数据总线16位,地址总线20位,于是寻找的范围必然受限于20位的地址总线,所以寻找范围无法超过1M(2^20).要想实现4GB的寻址,我们必须使用32位来表示地址,intel是这么解决这个问题的,他们用连续的8个字节组成的结构体来解决一系列问题: byte0 byte1 ….. byte7
其中,字节2,3,4以及字节7,这四个字节合在一起总共有32位,这就形成了一个32位的地址。同时把字节0,字节1,以及将字节6的拆成两部分,各4个bits,前4个bits跟字节0,字节1合在一起,形成一个20个bit的数据,用来表示要访问的内存长度。这样,我们就解决了内存寻址的问题。
选择子

保护模式寻址
1、段寄存器中存放段选择子Selector
2、GDTR中存放着段描述符表的首地址
3、通过选择子根据GDTR中的首地址,就能找到对应的段描述符
4、段描述符中有段的物理首地址,就得到段在内存中的首地址
5、加上偏移量,就找到在这个段中存放的数据的真正物理地址。
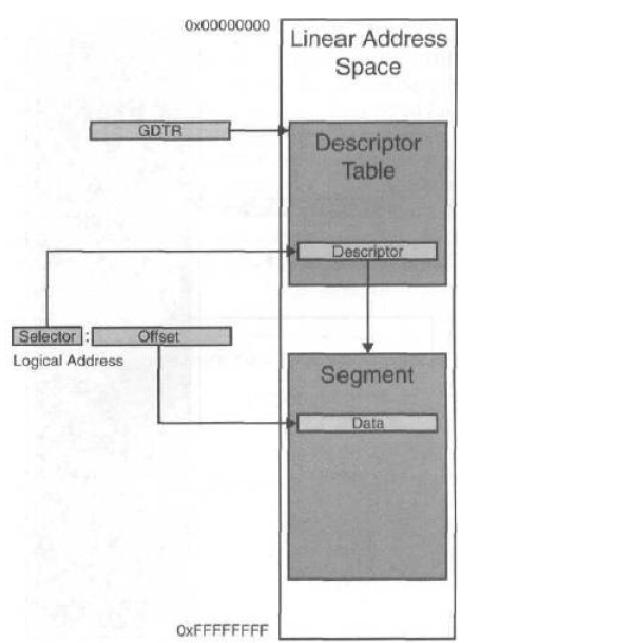
图中,通过Selector(段选择子)找到存储在Descriptor Table(描述符表)中某个Descriptor(段描述符),该段描述符中存放有该段的物理首地址,所以就可以找到内存中真正的物理段首地址Segment
Offset(偏移量):就是相对该段的偏移量 物理首地址 + 偏移量 就得到了物理地址 本图就是DATA
pmtest1
进入保护模式的主要步骤
准备GDT
1
2
3
4
5
6
7
8
9
10
11
12
13
14[SECTION .s16]
[BITS 16]
LABEL_BEGIN:
mov ax, cs
mov ds, ax
mov es, ax
mov ss, ax ;以上代码将当前的ds,es,ss全部指向cs代码段
mov sp, 0100h ;sp设置为0100h
; 初始化 32 位代码段描述符
xor eax, eax ;eax清0
mov ax, cs ;存入cs
shl eax, 4 ;左移4位,扩展为20位地址
add eax, LABEL_SEG_CODE32 ;在cs的基础上加上LABEL_SEG_CODE32的地址偏移(相对于0)用lgdt加载gdtr
1
2
3
4
5
6
7
8
9; 为加载 GDTR 作准备
xor eax, eax ;eax清0
mov ax, ds ;ds移入ax
shl eax, 4 ;扩展为20位
add eax, LABEL_GDT ; eax <- gdt 基地址 ds+gdt基地址
mov dword [GdtPtr + 2], eax ; [GdtPtr + 2] <- gdt 基地址 将gdt基地址移入GdtPtr中 GdtPtr也是个小的数据结构,它有6个字节,前两个字节是GDT的长度GdtLen,后四个字节是GDT的基地址
; 加载 GDTR
lgdt [GdtPtr];将GdtPtr中的GDT界限和GDT基地址加载到寄存器gdtr中打开A20
为什么要打开? 因为8086中【段:偏移】这样的模式能表示的最大内存是FFFF:FFFF,即10FFEFh,可是8086只有20位地址总线,只能寻址到1MB,那么如果试图访问超过1MB的地址时,系统会卷回去,重新从地址零开始寻址。可是到了80286时,真的可以访问到1MB以上的内存了,如果遇到同样的情况,系统不会再回卷寻址,这就造成了向上不兼容,为了保证百分百兼容,IBM想出一个办法,使用8042键盘控制器来控制第20个(从零开始数)地址位,这就是A20地址线,如果不被打开,第20个地址位将会总是零。所以为了访问所有的内存,我们需要把A20打开,开机时它是默认关闭的。
打开的方式? 只使用通过操作端口92h来实现这一种方式。
1
2
3
4; 打开地址线A20-----前面的段地址已经扩展位20位
in al, 92h
or al, 00000010b
out 92h, al置cr0的PE位
1
2
3
4; 准备切换到保护模式
MOV EAX, cr0
OR EAX, 1
MOV cr0, EAX寄存器cr0的第0位是PE位,此位为0时,CPU运行于实模式,为1时,CPU运行于保护模式。
跳转,进入保护模式
在置cr0的PE位为1时,系统就运行于保护模式之下了,但是此时CS【CS 指令段寄存器 (Code)用于保存当前执行程序的指令段(code segment)的起始地址】的值仍然是实模式下的值,我们需要把代码段的选择子装入CS,也就是
1 | JMP dword SelectorCode32:0 ; 执行这一句会把 SelectorCode32 装入 cs, 并跳转到 Code32Selector:0 处 |
但需要注意,修饰符dword是必要的,因为目的地址是32位【保护模式】
pm.inc

pm.inc里面的宏定义就是我们说的7字节数据结构, %macro Descriptor 3 表示要初始化该数据结构,需要传入3个参数,%1表示引用第一个参数,%2表示引用第二个参数。初始化该结构时,输入的一个参数是内存的地址,
大家看语句: dw %1 & 0FFFFh db (%1>>16) & 0FFh 这两句就是把内存地址的头三个字节放入到byte2,byte3,byte4, 最后一句: db (%1 >> 24) & 0FFh 就是讲地址的第4个字节放入到byte7. 初始化数据结构的第二个参数表示的是要访问的内存的长度,大家看语句: dw %2 & 0FFFFh 就是把内存长度的头两个字节写入byte0,byte1,语句: dw ((%2 >> 8) & 0F00h) | (%3 & 0F0FFh) 中的((%2 >> 8) & 0F00h)就是把内存长度的第16-19bit写入到byte6的前4个bit.由此要访问的内存和内存的长度就都设置好了,
pmtest2【保护模式进阶】
目标:有始有终,从保护模式返回实模式。
怎么检验?:由于在实模式下内存寻址空间仅仅只有1MB,因此这部分代码新增了一个数据段和一个名为TEST的段,其中TEST段的基地址位于5MB处,这远远超出了理论上实模式的寻址范围,代码想要完成的事情首先是要从TEST段的首地址位置读出8字节的内容,然后再向TEST段的首地址处写入完全不同的8个字节(这部分字符保存在新增的数据段中),然后再从5MB地方读出8个字节。也就是说,如果能够跳转成功,那么两次得到的字符串的将会是完全不同的,反之则会失败。
思考:从实模式进入保护模式进行跳转就好了,但从保护模式返回实模式稍复杂,因为结束保护模式回到实模式之前,需要加载一个合适的描述符选择子到有关段寄存器,以使对应段描述符高速缓冲寄存器中含有合适的段界限和属性,而且,我们不能从32位代码段返回实模式,只能从16位代码段中返回。这是因为无法实现从32位代码段返回时cs高速缓冲寄存器中的属性符合实模式的要求(实模式不能改变段属性)。所以我们新增一个Normal描述符,在返回实模式之前把选择子SelectorNormal加载到ds、es和ss。
- [section .s16code]
1 | ; 16 位代码段. 由 32 位代码段跳入, 跳出后到实模式 |
在[section.s16code]这个段中,开头的语句把SelectorNormal赋给ds、es、fs和ss,完成先前在思考里面讲的返回实模式之前就加载选择子,之后清零cr0的PE位,之后的跳转 JMP 0:LABEL_REAL_ENTRY看似段地址选择为了0,实际上在s16段的开始部分将会对段地址作出相应的修改,使程序能够正常的返回到实模式之中。所以我们回过头看LABEL_REAL_ENTRY
1 | LABEL_REAL_ENTRY: ; 从保护模式跳回到实模式就到了这里 |
LABEL_REAL_ENTRY,这是由保护模式跳转回实模式时所进入的地址,在这个地址下重新设置各个寄存器的值,恢复sp的值,然后关闭A20地址线,打开中断,将控制权重新交还给DOS。
[section.s32]
```NASM
[SECTION .s32]; 32 位代码段. 由实模式跳入.
[BITS 32]LABEL_SEG_CODE32:
MOV AX, SelectorData
MOV DS, AX ; 数据段选择子
MOV AX, SelectorTest
MOV ES, AX ; 测试段选择子
MOV AX, SelectorVideo
MOV gs, AX ; 视频段选择子MOV AX, SelectorStack
MOV SS, AX ; 堆栈段选择子MOV ESP, TopOfStack
; 下面显示一个字符串
MOV AH, 0Ch ; 0000: 黑底 1100: 红字
XOR ESI, ESI
XOR EDI, EDI
MOV ESI, OffsetPMMessage ; 源数据偏移
MOV EDI, (80 * 10 + 0) * 2 ; 目的数据偏移。屏幕第 10 行, 第 0 列。
CLD
.1:
lodsb
TEST AL, AL
JZ .2
MOV [gs:EDI], AX
ADD EDI, 2
JMP .1
.2: ; 显示完毕CALL DispReturn
CALL TestRead
CALL TestWrite
CALL TestRead; 到此停止
JMP SelectorCode16:01
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
- 让ds指向新增的数据段,es指向新增的5MB内存的段,gs指向显存
- 接着显示一行字符串,然后调用三个函数TestRead,TestWrite,TestRead【读写大地址内存】
- TestRead中调用了DispAL和DispReturn两个函数,DispAL将al中的字节用十六进制数的形式显示出来,DispReturn模拟一个回车的显示【也就是让下一个字符显示在下一行的开头处】
- 需要注意的是edi始终指向要显示的下一个字符的位置,所以如果程序中除显示字符外还要用到edi,需要事先保存它的值,以免在显示时产生混乱。
```NASM
; ------------------------------------------------------------------------
TestRead:
XOR ESI, ESI
MOV ECX, 8
.loop
MOV AL, [ES:ESI]
CALL DispAL
INC ESI
LOOP .loop
CALL DispReturn
RET
; TestRead 结束-----------------------------------------------------------
; ------------------------------------------------------------------------
TestWrite:
PUSH ESI
PUSH EDI
XOR ESI, ESI
XOR EDI, EDI
MOV ESI, OffsetStrTest ; 源数据偏移
CLD
.1:
lodsb
TEST AL, AL
JZ .2
MOV [ES:EDI], AL
INC EDI
JMP .1
.2:
POP EDI
POP ESI
RET
; TestWrite 结束----------------------------------------------------------
; ------------------------------------------------------------------------
; 显示 AL 中的数字
; 默认地:
; 数字已经存在 AL 中
; edi 始终指向要显示的下一个字符的位置
; 被改变的寄存器:
; ax, edi
; ------------------------------------------------------------------------
DispAL:
PUSH ECX
PUSH EDX
MOV AH, 0Ch ; 0000: 黑底 1100: 红字
MOV DL, AL
SHR AL, 4
MOV ECX, 2
.begin:
AND AL, 01111b
CMP AL, 9
JA .1
ADD AL, '0'
JMP .2
.1:
SUB AL, 0Ah
ADD AL, 'A'
.2:
MOV [gs:EDI], AX
ADD EDI, 2
MOV AL, DL
LOOP .begin
ADD EDI, 2
POP EDX
POP ECX
RET
; DispAL 结束-------------------------------------------------------------
; ------------------------------------------------------------------------
DispReturn:
PUSH EAX
PUSH EBX
MOV EAX, EDI
MOV BL, 160
DIV BL
AND EAX, 0FFh
INC EAX
MOV BL, 160
MUL BL
MOV EDI, EAX
POP EBX
POP EAX
RET
; DispReturn 结束---------------------------------------------------------
总代码:
1 | ;pmtest2.asm |
pmtest3【讲讲LDT】
这段代码的主要作用也是由实模式跳转到保护模式并打印出一个字符,然后再次跳转回实模式并返回DOS,与之前的pmtest2不同的是,这段代码新增对于LDT(局部描述符表)的使用过程。下面我们来具体看一下代码:
首先还是来看GDT的部分,GDT中新增了一个LDT的描述符,以及对应的选择子
1 | [SECTION .gdt] |
下面我们找到LDT对应的段,可以看到LDT描述符和选择子的定义与GDT几乎相同,而这里仅仅定义了一个LDT的描述符—— LABEL_LDT_DESC_CODEA,让我们查看一下它的代码
1 | ;LDT |
可以看到LDT和GDT的区别并没有在这些代码中显示出来,而实际上,它们的区别在于选择子稍有不同,LDT的选择子中多了一个SA_TIL的属性,SA_TIL将选择子的TI位置为1,那么此时系统将从当前的LDT中寻找相应的描述符。


LDT和GDT从本质上说是相同的,只是LDT嵌套在GDT之中。LDTR记录局部描述符表的起始位置,与GDTR不同LDTR的内容是一个段选择子。由于LDT本身同样是一段内存,也是一个段,所以它也有个描述符描述它,这个描述符就存储在GDT中,对应这个表述符也会有一个选择子,LDTR装载的就是这样一个选择子。LDTR可以在程序中通过使用lldt指令随时改变。
特权级
在IA32的分段机制中,特权级总共由4个特权级别,从高倒地分别是0、1、2、3。数字越小表示的特权级越大。

CPL\DPL\RPL
处理器通过识别CPL、DPL、RPL这3种特权级进行特权级检验
CPL(Current Privilege Level):CPL是当前执行的程序或任务的特权级。通常情况下,CPL等于代码所在的段的特权级,当程序转移到不同特权级的代码段时,处理器将改变CPL。如果遇到一致代码段,情况稍微特殊,因为一致代码段可以被相同或者耕地特权级的代码访问。当处理器访问一个与CPL特权级不同的一致代码段时,CPL不会被改变。
DPL(Descriptor Privilege Level):DPL表示段或者门的特权级。它被存储在段描述符或者门描述符的DPL字段中

RPL(Requested Privilege Level)
指程序或任务所在段所对应的选择子的第0位和第 1 位所代表的值。处理器比较 RPL 和 CPL 来判断是否为一个合法访问,即选择 CPL 与 RPL 较大的值来判定是否有权执行某一访问动作。
RPL可以很好的限制用户态程序对于内核态内存的访问。用户态程序执行系统调用或中断等转移到内核态执行时,在内核态执行时的RPL由调用者使用的选择子来决定,从而保证了用户态执行时的 RPL 仍然是用户态权限,所能访问的内存仍仅限于用户态内存。
特权级检验
对于数据的访问,只要CPL和RPL都小于被访问的数据段的DPL就可以了。
如果CPL > max (RPL,DPL) ,或者max (CPL,RPL) > DPL**,那么该访问就是不合法的,处理机就会产生一个常规保护异常(GP,General Protection Exception)
不同特权级代码段之间的转换
特权级是以段为单元来划分的,故特权级的转移必然伴随着代码段之间的跳转。程序从一个代码段跳转到另外一个代码段之前,目标代码段的选择子会加载到 cs 中。但是在加载的过程中,系统会根据当前现状进行特权级、类型、代码段界限等进行检查,若检查通过,则进行跳转。
程序控制权的转移可通过指令 jmp、call、int, ret, sysenter、sysexit、iret等,也可由硬中断和异常引起。
使用jmp 和call 实现以下 4 种转移:
- 目标操作数包含目标代码段的选择子
- 目标操作数指向一个包含目标代码段选择子的调用门描述符
- 目标操作数指向一个包含目标代码段选择子的TSS
- 目标操作数指向一个任务门,这个任务门指向一个包含目标代码段选择子的TSS
这4种方式可以看做是两大类,一类是通过Jmp和call的直接转移(上述第一种),另一类是通过某个描述符的间接转移(上述第2、3、4种)
通过jmp 或 call 进行直接转移
- 如果目标是非一致代码段,要求CPL必须等于目标段的DPL,同时要求RPL小于等于DPL。
- 如果目标是一致代码段,则要求CPL大于或等于目标段的DPL,RPL此时不做检查。当转移到一致代码段后,CPL会被延续下来,而不会变成目标代码段的DPL。
- 如果是在段内跳转的话,不需要检查特权级,如果是在段间的话,需要检查特权级
门描述符
门描述符怎么转移到目标代码
类似于GDT。
先从门描述符中的选择子得到目标代码的段描述符,从段描述符中得到段基址,之后加上门描述符中的偏移,最终得到目标代码的入口点。
retf指令
远返回指令。当它执行时,处理器先从栈中弹出一个字到IP,再弹出一个字到CS。
门描述符的定义
一个门描述了由一个选择子(选择的是操作系统核心的段)和一个偏移所指定的线性地址,程序正是通过这个地址进行转移的。
可以分为:
1.调用门
2.中断门
3.陷阱门
4.任务门
调用门本质上是一个入口地址,只是增加了若干属性
长调用与短调用【far和near调用】
如果一个调用或跳转指令是在段间而不是段内进行的,那么我们称之为“长”的,反之,如果在段内则是“短”的。
长的和短的jmp或call有什么不同呢?对于jmp而言,仅仅是结果不同罢了,短跳转对应段内,而长跳转对应段间;而call的话则会影响堆栈。【补充,call相当于调用函数,是需要把esp和EIP压栈的,jmp相当于goto,不需要压。
短调用
指令格式: CALL 立即数/寄存器/内存
发生改变的寄存器 ESP EIP【ESP寄存器提供程序堆栈中的偏移值,IP指令指针】
长调用(跨段不提权):
指令格式:CALL CS:EIP
发生改变的寄存器 ESP EIP CS
调用时会先PUSH调用者的CS,再PUSH返回地址【CS 指令段寄存器 (Code) 用于保存当前执行程序的指令段(code segment)的起始地址】
长调用(跨段并提权):
指令格式:CALL CS:EIP(EIP废弃)
发生改变的寄存器 ESP EIP CS SS【ESP:32位栈顶指针,EIP表示指令指针,CS表示指令段,SS表示栈寄存器(发生了堆栈切换)】
【期末考】Linux不同特权级之间代码跳转发生的堆栈切换 + 从被调用过程返回描述
堆栈切换及控制过程转移:
- 根据目标代码段的DPL,从TSS中选择新堆栈的指针。
- 读取当前代码段的堆栈选择子SS和栈顶指针ESP
- 暂时保存SS和ESP
- 加载新的堆栈段选择子SS和栈顶指针ESP
- 把第三步保存的SS和ESP压入新栈
- 从旧栈中复制参数到新栈中
- 将当前CS和EIP寄存器压入新栈中,便于返回地址
- 加载调用门指定的段选择子和指令指针到CS和EIP中,执行被调用过程。

跨特权级转移的返回
- 检查CS上的RPL域看返回时是否需要切换特权级
- 加载保存在被调用者栈上的CS和EIP寄存器信息【pop cs and eip】(也就是我们要返回的地址)
- 如果此时堆栈含有参数,则增加esp跳过参数,让esp指向保存在被调用者堆栈上的SS和ESP
- 加载当前esp所指的ss和esp【此时发生堆栈转换】
- 如果ret指令有参数计数部分,则增加ESP的值跳过栈上的参数部分。
- 检查DS,ES,FS,GS寄存器,如果某个寄存器的DPL小于当前特权级CPL,则该寄存器加载一个空描述符【不懂】
TSS的作用?
(不同特权级的代码段间的转移,会发生堆栈切换,使得调用者的入栈的堆栈是针对调用者本身的堆栈, 而出栈操作是针对被调用者的堆栈,即入栈和出栈的堆栈不一致,使得特权级间跳转出错,故引入了 TSS)
(2.2)转移的过程中,CPU所做的工作:
- 1) 根据目标代码段的DPL,从TSS中选择应该切换到哪个ss 和 esp;
- 2) 从TSS 中读取新的ss 和 esp。在这个过程中,若发现ss、esp 或者 TSS 界限错误都会导致无效 TSS异常;
- 3) 对ss 描述符进行检验,若发生错误,同样产生#TS异常;
- 4) 暂时性保存当前ss 和 esp 的值;
- 5) 加载新的 ss 和 esp;
- 6) 将刚刚保存起来的ss 和 esp 的值压栈;
- 7) 从调用者堆栈中将参数 复制到被调用者堆栈中(新堆栈中), 复制参数的数目由调用门中 Param Count一项来决定;
- 8) 将当前的 cs 和 eip 压栈;
- 9) 加载调用门中指定的新的cs 和 eip, 开始执行被调用者过程;
(2.2)从被调用者到调用者的返回过程中, 处理器的工作:
(实际上,ret这个指令不仅可以实现短返回和长返回, 而且可以实现带有特权级变换的长返回)
- 1)检查保存的cs 中的RPL 以判断返回时是否要变换特权级;
- 2)加载被调用者堆栈上的cs 和eip;
- 3)如果ret 指令含有参数,则增加esp 跳过参数,然后esp 将指向被保存过的调用者ss 和 esp ;ret的参数个数对应 调用门中的 Param Count的值;
- 4)加载ss 和 esp , 切换到调用者堆栈,被调用者的ss 和 esp 被丢弃;
- 5)如果ret 指令含有参数, 增加esp 的值以跳过参数;
- 6)检查ds、es、fs、gs的值,如果其中哪一个寄存器指向的段的DPL 小于CPL(此规则不适用于一致代码段),那么一个空描述符会被加载到该寄存器;
【3】总结:(使用调用门的过程实际上分为两部分)
- (1)从低特权级到高特权级,通过调用门和call 指令来实现;
- (2)从高特权级到低特权级, 通过ret 指令来实现;(即,ret 指令可以实现从高特权级到低特权级的转移)
进程影像
进程回顾
定义:一个正在执行的程序/一个正在计算机上执行的程序实例
PCB:进程控制块是存放进程表征元素的模块,它包括:标识符,状态,优先级,程序技术收起,内存指针,上下文,I/0状态信息,记账信息
进程映像(Process Image)是某一时刻进程的内容及其执行状态集合,是内存级的物理实体,又称为进程的内存映像,一般包括了代码段、数据段、栈段、PCB。
ELF(可执行与可链接文件格式)
ELF的组成:分为四部分,ELF头(ELF header)、程序头表(Program header table)、节(Section)和节头表(Section header table)。
目标文件ELF结构
.text – 节中是可执行二进制代码
.data – 节中保存已初始化的全局变量和局部静态变量
.bss – Block Started by Symbol,节中保存未初始化的全局变量和局部静态变量【其他变量就在调用时动态地在堆栈中分配空间】
.rodata – 节中保存只读数据,对应”Hello Linux World!”
.comment – 节中包含注释信息
.note – 额外的编译信息,例如程序的公司名、版本等
.eh_frame – 与异常处理有关的信息(Exception handling)
源代码与目标文件的对应关系

可执行文件与进程虚地址空间对应关系
一个可执行文件被执行的同时也伴随着一个新的进程的创建。Linux会为这个进程创建一个新的虚拟地址空间,然后会读取可执行文件的文件头,建立虚拟地址空间与可执行文件的映射关系,然后将CPU的指令指针寄存器设置成可执行文件的入口地址,然后CPU就会从这里取指令执行。
虚拟地址空间与可执行文件的映射关系如何建立的?
问你的是可执行文件映射怎么建立。
这种映射关系只是保存在操作系统内部的一个数据结构。Linux中将进程虚拟空间中的一个段叫做虚拟内存区域(VMA,Virtual Memory Area)。在将目标文件链接成可执行文件的时候,链接器会尽量把相同权限属性的段分配在同一空间。比如可读可执行的段都放在一起,这种段的典型是代码段【code segment(code vma)】;可读可写的段都放在一起,这种段的典型是数据段【 data segment(data vma)】。在ELF中,把这些属性相似的,又连在一起的段叫做一个“segment”,将这个segment映射到进程虚拟地址空间中的一个VMA中
【简单来说,目标文件中属性相近的节(可读可写、可读可执行)会在链接成执行文件的时候,分配在相同的空间,称之为段(segment),然后在装载的时候,将这个segment映射到进程虚拟地址空间中的一个VMA中】

Linux把虚拟空间的一个段叫做虚拟内存区域。在将目标文件链接成可执行文件时,会将属性相同【如可读可写、可读可操作】的段分配在同一空间,ELF中称之为segment,之后在装载的时候,再将这个segment映射到虚拟进程空间的VMA中。
【期末考】进程映象如何描述(2021.11.26)【进程的虚地址空间如何描述】
【据说是重点会考】
每个进程 (task_struct) 都会有一个内存管理记录(mm_struct),此外进程的地址空间会被分成多个区域,每个区域描述的是一段连续的、具有相同访问属性的虚存空间,该虚存空间的大小为物理内存页面的整数倍。在这里,每个区都会通过一个(vm_area_struct)描述,通常,进程所使用到的虚存空间并不不连续,且各部分虚存空间的访问属性也可能不同。所以一个进程的虚存空间需要多个 vm_area_struct 结构来描述。进程的各个区域按照两种方式维护:
- 在一个单链表上(开始于 mm_struct–>mmap)
- 在一个红黑树中,根节点存储在 mm_rb
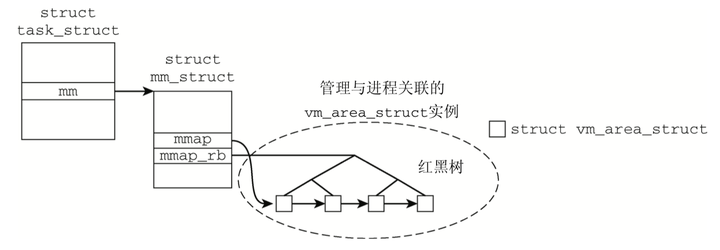
用户虚拟地址空间中的每个区域都有一个开始地址和一个结束地址。现存的区域按起始地址以递增次序被归入链表中。当内存区域很多时,如果只是通过扫链表来找到与特定地址关联的区域,显然效率会很低。因此 vm_area_struct 的各个实例还通过红黑树管理,这可以显著加快扫描速度。增加新区域时,内核首先搜索红黑树,找到刚好在新区域之前的区域。然后,内核可以向树和线性链表添加新的区域,而无需扫描链表。
【自己的注解:Linux内核中有种数据结构task_struct(进程控制块),它会被装载在RAM中,每个task_struct中都有个内存管理的数据结构mm_struct用于描述本进程地址空间,此外进程的地址空间会被划分为多个区域,每个区描述的是一段连续的、具有相同访问属性的虚存空间,Linux中用vm_area_struct描述这个区,一般来说,进程用到的虚地址空间不是连续的,且各个区的访问属性也不相同,因此一个进程的虚地址空间需要多个vm_area_struct进行描述,进程一般采用两种方式维护这部分虚存空间:
通过一个单链表:开始于mm_sturct–>mmap
通过一个红黑树:根节点位与mmap_rb。
这部分虚地址空间的每个区域都有一个开始地址和一个结束地址,被按照递增次数归入链表,因此,当内存区域很多时,再使用链表维护的话查找效率太低,故采用红黑树。】


引入红黑树是为了提高效率,单查找vma的链表太慢了
会画上述这三个图
物理存储
参考:https://blog.csdn.net/weixin_42452328/article/details/113535364
在一个计算机系统内部,两个以上的CPU共享对一个公共RAM都拥有的完全访问权限. 根据不同CPU读写速度的不同又分为NUMA和UMA
UMA ( Uniform Memory Access , 统一内存访问)
每个存储器字的读出速度是一样快的。
主要有三种硬件实现
- Bus-Based Architectures 总线结构
- Crossbar Switches 交叉开关
- Multistage Switching Networks 多级交换网络
SMP
对称多处理(英语:Symmetric multiprocessing,缩写为SMP),也译为均衡多处理、对称性多重处理,是一种多处理器的电脑硬件架构,在对称多处理架构下,每个处理器的地位都是平等的,对资源的使用权限相同。现代多数的多处理器系统,都采用对称多处理架构,也被称为对称多处理系统(Symmetric multiprocessing system),其组织方式如下图所示:

NUMA(Non-uniform Memory Access)
如果物理内存是分布式的,由多个cell组成(比如每个核有自己的本地内存),那么CPU在访问靠近它的本地内存的时候就比较快,访问其他CPU的内存或者全局内存的时候就比较慢,这种体系结构被称为Non-Uniform Memory Access(NUMA)。
以上是硬件层面上的NUMA,而作为软件层面的Linux,则对NUMA的概念进行了抽象。即便硬件上是一整块连续内存的UMA,Linux也可将其划分为若干的node。同样,即便硬件上是物理内存不连续的NUMA,Linux也可将其视作UMA。
ZONE
node_zone:存储该节点的区域,用区域来区分不同的物理内存。
三种类型的zone:
ZONE_DMA:DMA方式可以操作的内存区域;
ZONE_NORMAL:普通的映射区;
ZONE_HIGHMEM:高端内存映射的区域。
free_area:空闲page的数组 + 链表的结构,伙伴系统依靠该数据结构来分配物理内存。每个数组的item都是一个链表,链表中的每个item就是待分配的单元,其大小为2的n次方个页,n为数组下标。MAX_ORDER = 11,一次可以分配2的11次方个页,即M内存。
1 | struct zone { |
NODE
Node是内存管理最顶层的结构,在NUMA架构下,CPU平均划分为多个Node,每个Node有自己的内存控制器及内存插槽。CPU访问自己Node上的内存时速度快,而访问其他CPU所关联Node的内存的速度比较慢。而UMA则被当做只有一个Node的NUMA系统。
内核中使用struct pglist_data来描述一个Node节点
1 | typedef struct pglist_data { |
Page
用于表示一个4k页面的meta信息,如果内存为4G,则有1M个page,如果page占用空间太大,则用户实际可使用的内存就会变少,而page的使用方式有多种,需要meta记录下来,所以内部大量使用union,page目前实际大小为32byte,就是4G的内存,需要使用32M来保存meta信息。
总结:Linux如何管理物理内存。
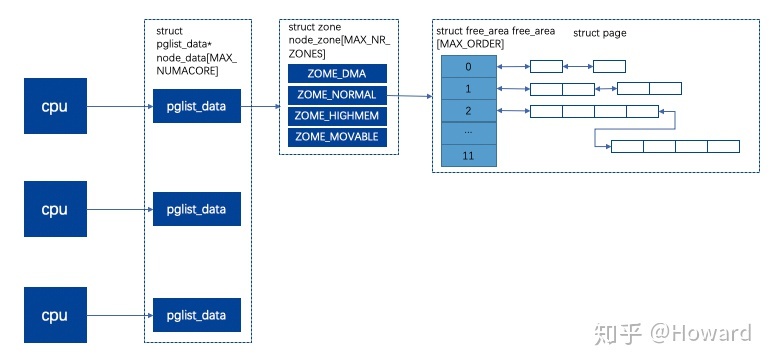
采用NUMA架构,将物理内存视为分布式的,由多个cell组成,那么CPU在访问靠近它的本地内存的时候就比较快,访问其他CPU的内存或者全局内存的时候就比较慢。
之后声明若干个pglist_data,其管理某cpu对应指定的内存节点,pglist_data中包含node_zone数组、node_zonelist数组、mem_map数组三个重要的字段:mem_map数组包含了该node上所有的struct page,包括已分配、未分配的,也用于物理页号映射。;node_zone数组存储该pglist_data节点上所有的zone,node_zonelist数组存储其他节点的zone,当cpu的pglist_data -> mem_map的page用完后,可以通过该数组申请其他cpu的内存。
cpu–>pglist_data–>node_zone,Linux中用node_zone来管理存储该节点的区域,它将属性相同的page frames归到一个zone中,共有三种类型的zone,同时node_zone中还声明了free_area结构,用于实现伙伴系统。
cpu–>pglist_data–>node_zone–>page:节点描述信息的基本单元。用于表示一个4k页面的meta信息,如果内存为4G,则有1M个page。
在NUMA系统中,当Linux内核收到内存分配的请求时,它会优先从发出请求的CPU本地或邻近的内存node中寻找空闲内存,这种方式被称作local allocation,local allocation能让接下来的内存访问相对底层的物理资源是local的。
每个node由一个或多个zone组成(我们可能经常在各种对虚拟内存和物理内存的描述中迷失,但以后你见到zone,就知道指的是物理内存),每个zone又由若干page frames组成(一般page frame都是指物理页面)。
伙伴系统:其实就是个二叉树,二分整个区间,若存储空间在子区间内,则分配,不满足,则继续分裂

外部中断
硬盘——快速交换(a bulk of bytes)
APIC:Advanced Programmerable Interupt Controler
外部中断
外部中断指硬件中断,一般由外部硬件设备引发的中断。
可以用指令来屏蔽外部中断(如CTL,STL),也有不可屏蔽的【nmi】
总是在CPU执行完一条指令之后去检查,再发生的。【而异常是在执行的过程中发生的】
软中断
软件中断,一般通过指令来主动发出的中断
在Intel X86计算机上通过软件指令INT n发出
何时发出软中断是程序员根据程序逻辑的需要安排的,程序员非常清楚软中断何时会发生,因此软中断是“主动的”、“同步的”
主动的软件中断又被称为陷阱。(陷入到操作系统核心 Trap 自陷)
为什么要关闭软件中断?软件中断是不需要被屏蔽的,比如调用INTER80中断,是我自己选择的,所以只需要自己关闭就好了。
期末考试:请说明X86保护模式下中断的响应过程 LKA-05-10
ISR interupt service routing
IDT interrupt descriptor table 中断描述符表
IDTR【中断门描述符】 共有3类:
- 任务门:当中断信号发生时,必须取代当前进程的那个进程的TSS选择符存放在任务门中。
- 中断门:包含段选择符和中断或异常处理程序的段内偏移量.当控制权转移到一个适当的段时,处理器 清IF标志,从而关闭将来会发生的可屏蔽中断.
- 陷阱门:与中断门相似,只是控制权传递到一个适当的段时处理器不修改IF标志
思考目的:
检测,找到对应中断服务程序与其起始地址。
详细过程:
0.中断响应的事先准备:
系统将所有的中断信号统一进行了编号(一共256个:0~255),称之为中断向量。中断向量和中断服务程序的对应关系主要是由IDT(中断向量表)负责。操作系统在IDT中设置好各种中断向量对应的中断描述符(一共有三类中断门描述符:任务门、中断门和陷阱门),留待CPU查询使用。
【注:中断服务程序具体负责处理中断(异常)的代码是由软件,也就是操作系统实现的,这部分代码属于操作系统内核代码。也就是说从CPU检测中断信号到加载中断服务程序以及从中断服务程序中恢复执行被暂停的程序,这个流程基本上是硬件确定下来的,而具体的中断向量和服务程序的对应关系设置和中断服务程序的内容是由操作系统确定的。】
1.CPU检查是否有中断/异常信号:
CPU执行完当前程序的每一条指令后,都会去确认在执行刚才的指令过程中中断控制器是否发送中断请求过来。
2.根据中断向量到IDT表中取得处理这个向量的中断程序的段选择符:
CPU根据得到的中断向量到IDT表里找到该向量对应的中断描述符,中断描述符里保存着中断服务程序的段选择符。
3.根据取得的段选择符【IDTR】到GDT中找相应的段描述符【GDTR】
根据IDTR,从GDT中取得相应的段描述符,段描述符里保存了中断服务程序的段基址和属性信息,此时CPU就得到了中断服务程序的起始地址。【或者可以说是拿给了ISR[interupt service routing]】
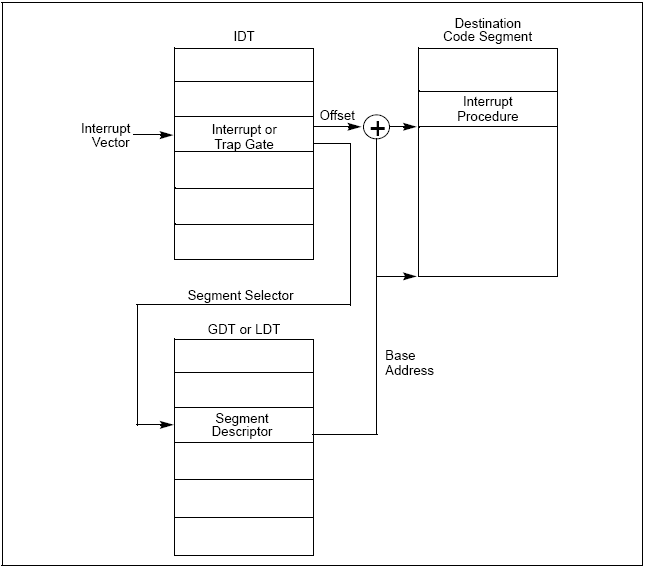
4.进行有效性检查:
分两步,首先是“段”级检查,将CPU的当前特权级CPL(存放在CS寄存器的最低两位)与IDT中第i项段选择符中的DPL【Descriptor Privilege Level】相比较,如果DPL(3)大于CPL(0),就产生一个“通用保护”异常,因为中断处理程序的特权级不能低于引起中断的进程的特权级。这种情况发生的可能性不大,因为中断处理程序一般运行在内核态,其特权级为0。
然后是“门”级检查,把CPL与IDT中第i个门的DPL相比较,如果CPL大于DPL,也就是当前特权级(3)小于这个门的特权级(0),CPU就不能“穿过”这个门,于是产生一个“通用保护”异常,这是为了避免用户应用程序访问特殊的陷阱门或中断门。但是请注意,这种“门”级检查是针对一般的用户程序,而不包括外部I/O产生的中断或因CPU内部异常而产生的异常,也就是说,如果产生了中断或异常,就免去了“门”级检查。
5.堆栈切换:
如果以上检查通过,且特权级发生了变化(内陷),则在TSS段中读取当前进程的SS和ESP到SS和ESP寄存器中,这样就完成了用户态栈到内核态栈的切换。
6.保存上下文
将CS、EIP等寄存器的值压入内核栈中,保存返回后需要执行的上下文。
7.最后进入中断处理程序的起始地址【第三步得到的】
IDT
interrupt descriptor table 中断描述符表
它是一个数组
0-31 给异常用的 X-XX给外部中断用的 X–XX给系统中断用的
一些数据
NR_IRQS=224。在单处理器的情况,interrupt[]数组中只有前16个函数指针有效,后续208(224-16=208)个函数指针为空。只有在支持SMP的情况下,后面的208个函数指针才可能有效
共256个中断入口
00-1FH留给异常和不可以屏蔽中断(NMI)
20-FFH留给可屏蔽中断和软中断,其中80H作为系统调用的入口
前16个外部中断进入了一段公共服务程序common_interrupt
SYSCALL_VECTOR就是80h &system_call是linux所有系统调用的入口
怎么知道调用的是哪个系统调用?先放到EAX这个寄存器中,看EAX的值是多少,就知道对应的调用是什么。
FIRST_EXTERNAL_VECTOR是32
set_intr_gate(vector, interrupt[i]); //256-32 80h占1 设置224-1=223个gate【外部中断】 也就是说这个循环设置了默认的循环,-1是为了排除80h
IDT初始化(LKA-05-16)
以下代码看注释!
1 | void __init trap_init(void) |
1 | void set_intr_gate(unsigned int n, void *addr) |
1 | //构造gate的宏 |
1 | //arch/i386/kernel/i8259.c |
1 | //arch/i386/kernel/i8259.c |
NR_IRQS=224。在单处理器的情况,interrupt[]数组中只有前16个函数指针有效,后续208(224-16=208)个函数指针为空。只有在支持SMP的情况下,后面的208个函数指针才可能有效
1 | //include/asm-i386/hw_irq.h … |
1 | //include/asm-i386/hw_irq.h … |
1 | //include/asm-i386/hw_irq.h … |
外部中断请求队列初始化
描述中断
1 | //include/linux/irq.h |
1 | //include/linux/irq.h |
NR_IRQS=224
1 | //arch/i386/kernel/i8259.c |
action的描述符
1 | struct irqaction { |
注册中断处理服务程序
1 | / arch/i386/kernel/irq.c |
外部中断的注册
谁来完成?驱动程序。
驱动程序可以通过request_irq()函数注册一个中断处理程序,并且激活给定的中断线。调用该函数所需的关键参数有:
1.irq:表示要分配的中断号。
2.handler指针:指向实际处理这个中断的中断处理程序
3.dev:用于共享中断线,dev用于提供标志信息,当一个中断处理程序需要释放的时候,我们可以通过dev从共享中断线的诸多中断处理程序中删除指定的一个。它也可以用来区分共享同一中断处理程序的多个设备。
调用返回0,则说明处理程序安装完毕,以后其会在响应该中断时被调用。
概述一下LInux如何动态注册外部中断?【期末考】——>中断请求队列
1.要让多个中断源共用中断,且允许共用的结构在系统允许过程中动态变化,需要在IDT初始化阶段为每个中断向量(表项)准备下一个“中断请求队列”,从而形成一个中断请求列队数组,也就是irq_desc[]。
2.在irq_desc数组中存放着NR_IRQS-1个irq_desc_t,irq_des_t中包含着用户注册的中断服务程序【已经注册的】的详细信息,比较重要的两个是handler指针和action指针,handler指针指明外部中断接在哪个外部中断处理器上,action指针指向irqaction列表,指明中断动作在哪,同时其为列表的原因是要让同一类外部设备共享一个外部中断,同时在action中有dev_id字段,用于指明主设备号和次设备号,主设备号区分哪一类设备,次设备号区分哪一个设备。【这里可以画一下第二幅图】


外部中断响应与服务

首先执行interput[i],它将中断向量号和被中断上下文(进程上下文或者中断上下文)保存到栈中(SAVE_ALL实现),最后调用do_IRQ函数。【保存现场】
之后执行do_IRQ,它是中断处理的核心函数,来到这里时,系统已经完成了两件事
- 系统屏蔽了所有可屏蔽中断(清除了CPU的IF标志位,由CPU自动完成)
- 将中断向量号和所有寄存器值保存到内核栈中
在do_IRQ中,首先会添加硬中断计数器,此行为导致了中断期间禁止调度发送,此后会根据中断向量号从vector_irq[]数组中获取对应的中断号,并调用handle_irq()函数得到该中断号对应的中断例程。
最后执行中断描述符中的handle_irq指针所指函数,或者说是中断服务例程(isr)完成响应。
时钟中断【补充】
与时钟中断有关的函数
下面我们看时钟中断触发的服务程序,该程序代码比较复杂,分布在不同的源文件中,主要包括如下函数:
- 时钟中断程序:**
timer_interrupt()**; - 中断服务通用例程
do_timer_interrupt(); - 时钟函数:
do_timer(); - 中断安装程序:
setup_irq(); - 中断返回函数:
ret_from_intr()
前三个函数的调用关系如下:
1 | timer_interrupt( ) |
重点看设置的次数跟时间之间的关系,也就是do_timer()。
1 | oid do_timer(struct pt_regs * regs){ |
在该函数中还有两个变量lost_ticks和lost_ticks_system,这是用来记录timer_bh()执行前时钟中断发生的次数。因为时钟中断发生的频率很高(每10ms一次),所以在timer_bh()执行之前,可能已经有时钟中断发生了,而timer_bh()要提供定时、记费等重要操作,所以为了保证时间计量的准确性,使用了这两个变量。lost_ticks用来记录timer_bh()执行前时钟中断发生的次数,如果时钟中断发生时当前进程运行于内核态,则lost_ticks_system用来记录timer_bh()执行前在内核态发生时钟中断的次数,这样可以对当前进程精确记费。【多两个变量辅助计数,lost_tricks记录time_br()执行前时钟中断发生次数,lost_tricks_system()记录在内核态发生时钟中断的次数。】
1 | setup_irq(0, &irq0); //设置时钟中断服务处理例程 |
系统调用
课堂笔记:
ATMT汇编 左边是要保存,右边是目的。
如:movl %ebx, %edx 是把ebx内容放到edx里面
1 | 0x4(%esp,1), %ebx //0x4(%esp,1) 意思是 0x4+esp 也就是esp+4 |
先把参数压栈,再压到寄存器,最后传。
eax中存放的是系统调用的返回值【是否成功】
系统调用(4),关键的代码有注释
1 | //arch/i386/kernel/entry.S |

同一个中断号【80h】是如何处理多个不同的系统调用的?
实际上,Linux中每个系统调用都有相应的系统调用号作为唯一的标识,内核维护一张系统调用表,sys_call_table,表中的元素是系统调用函数的起始地址,而系统调用号就是系统调用在调用表的偏移量。在x86上,系统调用号是通过eax寄存器传递给内核的。
系统调用是需要提供参数,并且具有返回值的,这些参数又是怎么传递的?
最简单的办法就是像传递系统调用号一样把这些参数也存放在寄存器里。在x86系统上,ebx, ecx, edx, esi和edi按照顺序存放前五个参数。给用户空间的返回值也通过寄存器传递。在x86系统上,它存放在eax寄存器中。
【期末考】如何实现某个系统调用?
画个图,辅以文字描述https://developer.aliyun.com/article/47658
用户态应用程序调用System Call的过程是:
将系统调用号存入EAX
把函数参数存入其他通用寄存器
通过中断调用【x86上触发0x80 号中断(int 0x80)】使系统进入内核态
内核中的中断处理函数根据系统调用号与sys_call_table
1
call sys_call_table(%eax,4); //其实也就是sys_call_table+eax*4
调用对应的内核函数【系统调用服务例程】
内核函数完成相应功能,将返回值存入EAX,返回到内核中的中断处理函数
将EAX中的返回值返回给应用程序,先判断返回值_res是否为非负数。若是,则说明该次调用是成功的,返回_res即可。若_res为负数,则说明该次调用过程中存在着一个或一些错误,将错误值赋给一全局变量errno:
1
errno = -_res;
再返回-1,指明有错误存在,可以让专门处理这些错误的函数根据errno的值知道这次调用到底出错在什么地方,是哪种类型的错,以便进行错误处理。
 |
 |
|---|---|
系统调用(8)

进程与进程调度
task_struct和系统堆栈
在Linux中task_struct相当于进程的进程控制块。
每个进程都有一个task_struct数据结构和一个系统(空间)堆栈
task_struct数据结构和系统(空间)堆栈位于连续的物理存储空间,大小为两个连续的物理页面 (Page Frame,8KB)
系统(空间)堆栈的大小不能在运行时动态扩展

堆栈?
- 用来保存返回的现场,如函数调用【需要保存ESP/EIP/CS/SS/FLAGS寄存器,保存地址是由硬件CPU完成,未完成的部分通过软件完成,LKA05中的SAVE_ALL指令】
- 传递参数,【什么参数?函数调用、系统调用】
进程的概念?
进程的定义:
- 一个正在执行的程序
- 一个正在计算机上执行的程序实例
- 能分配给处理器并由处理器执行的实体
- 由一组执行的指令,一个当前状态,和一组相关的系统资源表征的活动单元
进程与程序?
- 同一程序可以产生多个进程(一对多的关系),如游戏多开。
- 程序是静态的操作系统指令文件
- 进程是动态的,是操作系统进行资源分配的概念
多道程序设计?
多道程序设计是在计算机内存中同时存放几道相互独立的程序,使它们在管理程序控制之下,相互穿插地运行
线程的实现方式?
用户级线程 ULT
管理线程的所有工作都由应用程序完成,内核意识不到线程的存在,继续以进程为单位进行调度,并为进程指定一个状态。在ULT执行一个系统调用时,不仅会阻塞这个线程,也会阻塞进程中的所有线程。
内核级线程 KLT
线程管理的所有工作由内核完成,应用程序没有进行线程管理的代码,
混合
TSS和TR
TSS(Task State Segment)
作用:保存不同特权级的堆栈的栈顶指针,一次性切换许多寄存器。
特点:每个进程对应一个TSS,每个CPU对应一个TSS,因此TSS的数目取决于CPU的数目(NR_CPUS)
TR(Task Register)
特点:TR(Task Register)指向当前运行任务的TSS
进程族谱
父进程指向最年轻子进程
每个进程只有一个父进程,所以有指针指向它,通过孩子兄弟的关系完成。

一直不死的进程——daemon守护进程
创建进程的系统调用
1 | 有三个 |
fork
1 | fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值: |
task_struct描述符
CLONE_VM 使得vfork创建的子进程与父进程共享虚地址空间。
CLONE_VFORK——》会在新创建子进程时阻塞父进程,直到子进程execve或者exit
——》调用Vfork的情况即为创建一个子进程,让其立马去执行execve
1 | 调用Vfork的情况即为创建一个子进程,让子进程去执行某个操作 |
do_fork()
创建一个进程就是要根据系统调用fork、vfork、clone给出的参数,分配一个task_struct描述符,并复制/初始化关联数据结构,从而使得操作系统可以控制新创建的进程/线程(clone的结果可能是线程)
当系统调用fork()通过sys_fork()进入do_fork()时 ,clone_flags为SIGCHLD,即CLONE标志均为0,所以copy_files()、copy_fs()、copy_sighand、copy_mm()全都真正执行,四项资源全都复制了
当系统调用vfork()通过sys_vfork()进入do_fork()时,clone_flags为CLONE_VFORK | CLONE_VM | SIGCHLD,即CLONE标志为CLONE_VFORK | CLONE_VM| SIGCHLD,所以只执行了copy_files()、copy_fs()、copy_sighand,而copy_mm()因为CLONE_VM是1,只是通过指针与父进程共享存储空间
clone()完全根据传入参数有选择地复制父进程
copy_thread()复制父进程的系统空间堆栈,并且经过调整,使得父子进程各自从系统调用返回后可以进行区分
do_fork()如何创建一个新进程
建立进程控制结构并赋初值,使其成为进程映像。这个过程完成以下内容。
在内存中分配一个 task_struct 数据结构,以代表即将产生的新进程。
把父进程 PCB 的内容复制到新进程的 PCB 中。
为新进程分配一个唯一的进程标识号 PID 和 user_struct 结构。然后检查用户具有执行一个新进程所必须具有的资源。重新设置 task_struct 结构中那些与父进程值不同的数据成员。
编程题
产生一个进程树,父进程有2个子进程,这2个子进程分别又有2个子进程,每个进程休眠5秒后退出,并在退出前打印自己的进程id号。
1 |
|