写博客这个念头存在在我脑海里已经很久很久了。
时代的发展让我们拥有了更快捷的信息转递方式,更丰富的信息表达途径,随之而来的,是衍生出的一连串的社交帐号,社交平台。
早上在空间里吐槽一下,下午在朋友圈转转文章,晚上知乎里和杠精对对线。
正如唱戏的舞台多了,观众自然也会蛮蛮分散,观点的表达也被吞噬地七零八碎。
相对于表达自己的观点,我更喜欢倾听,倾听他人的观点。
可问题是,当他人给予的观点增多,冗杂的信息会让我无处消化,我需要这么一个平台。
它只是静静的躺在那里,既不崭露锋芒,也不沉默不语。
这就是我搭建这个博客的原因。
当然了,更多的,我想在这个博客中分享我大学的学习生活,学习历程。
它可以是树洞,是我的自留地,也可以是小伙伴们认识我这个俗人的途径(笑
总之,祝你今天愉快!
BusTub
MapReduce
MapReduce
基于《MapReduce: Simplified Data Processing on Large Clusters》和Mit 6.824课程,以go语言实现了 单机多进程 的 MapReduce 框架。通过设计实现Master主节点、Worker工作节点以及两者之间的RPC通信,模拟了分布式环境下的调度执行程序,错误恢复,以及管理所需的机器间通信。并通过该框架统计一个很大的文档集合中每个单词出现的次数。
特点
- 设计实现了MapReduce论文中的Master主节点,将M个map任务和R个reduce任务分配给空闲的工作节点,通过维护任务管道调度所有任务的运行,同时在分发任务的过程中进行互斥锁的添加与回退,防止多个worker竞争。
- 设计实现了MapReduce论文中的Worker工作节点,Worker节点可以在空闲时请求任务池里的任务,对相应的Map任务和Reduce任务进行解析并计算。对于Map任务读取对应的输入区块内容,计算解析出key/value对并缓存在本机;对于Reduce任务使用RPC调用得到Map工作节点的本地磁盘中的缓存数据,遍历并通过shuffle方法排序好所有的缓存数据,之后根据重排序好key/value数组重定向输出文件。
- 设计实现了错误恢复机制,通过中间文件存储和在Master开启一个协程追踪任务进行时间戳的方式,保证当Worker正在执行任务时突然宕机和卡死等情况下被执行的任务能够重新恢复并调度给其他空闲的工作节点。
CMU15445-018-Multi-VersionConcurrencyControl
CMU15445-017-TimestampOrderingConcurrencyControl
Timestamp Ordering Concurrency Control
时间戳排序(Timestamp ordering T/O)是一种乐观的并发控制协议
其中DBMS假设事务冲突很少。DBMS不要求事务在被允许读/写数据库对象之前获取锁,而是使用时间戳来确定事务的可串行化顺序。
每个事务Ti被分配一个唯一的固定时间戳TS(Ti),其单调递增。不同的方案在事务期间的不同时间分配时间戳。一些高级方案甚至为每个事务分配多个时间戳。
如果TS(Ti)<TS(Tj),则DBMS必须确保执行计划等同于串行计划,其中Ti出现在Tj之前。
有多种时间戳分配实现策略。DBMS可以使用系统时钟作为时间戳,但在夏时制等边缘情况下会出现问题。另一种选择是使用逻辑计数器。但是,这存在溢出问题,以及在具有多台计算机的分布式系统中维护计数器的问题。也有混合方法使用这两种方法的组合。
CMU15445-015-ConcurrencyControlTheory
事务(Transactions)
事务(Transaction) 是一种机制、一个操作序列,包含了一组数据库操作命令。
A transaction is the execution of a sequence of one or more operations (e.g., SQL queries) on a shared database to perform some higher level function. They are the basic unit of change in a DBMS. Partial transactions are not allowed (i.e. transactions must be atomic).
CMU15445-016-Two-PhaseLocking
事务锁(Transaction Locks)
分为两类
- Shared Lock 共享锁(S锁):允许多个事务同时读取同一对象的共享锁。如果一个事务持有共享锁,那么另一个事务也可以获取相同的共享锁。
- Exclusive Lock 专用锁(X锁):独占锁允许事务修改对象。此锁防止其他事务获取对象上的任何其他锁(S锁或X锁)。一次只有一个事务可以持有独占锁
事务必须从lock manager中请求或更新锁,lock manager根据其他事务当前持有的锁授予或阻止请求。
事务在释放对象的时候要释放锁
lock manager维护一张内部的lock-table,维护的的依据是哪些事务持有哪些锁以及正在等待获取锁的事务
DBMS的lock-table不需要是持久的,因为DBMS崩溃时处于活动状态的任何事务都会自动中止。
CMU15445-013&014-QueryPlanning&Optimization
SQL 是声明性的,所以查询只告诉DBMS需要计算什么,而不是如何计算。
所以DBMS需要将SQL语句转换为可执行的查询计划,但是在查询计划中有不同的方法来执行每个操作符,并且这些计划之间的性能会有所不同。
DBMS优化器的工作是为任何给定查询选择最佳计划。
查询优化有两种高级策略
heuristics 启发式
基于成本的搜索 选择最低成本的计划
查询优化是构建数据库管理系统中最困难的部分。一些系统试图应用机器学习来提高优化器的准确性和效率,但目前没有大型数据库管理系统部署基于这种技术的优化器。
CMU15445-012-Queryexecution2
CMU15445-06-HashTable
哈希方案分类(hash scheme)
静态哈希:静态哈希方案,这意味着我们在一开始分配内存时就需要知道希望保存的key的数量。
- 线性探针哈希(Linear Probe Hashing)
- 墓碑法(Tombstone)和移动法(Movement)解决删除时遇到的空slot问题
- 罗宾汉哈希(Robin Hood Hashing)
- 追求平衡,但会带来更多的缓存无效
- 布谷鸟哈希(Cuckoo Hashing)
- 线性探针哈希(Linear Probe Hashing)
动态哈希
- 链式哈希(Chained Hashing)
- 每个 key 对应一个链表,每个节点是一个 bucket,装满了就再往后挂一个 bucket。需要写操作时,需要请求 latch。
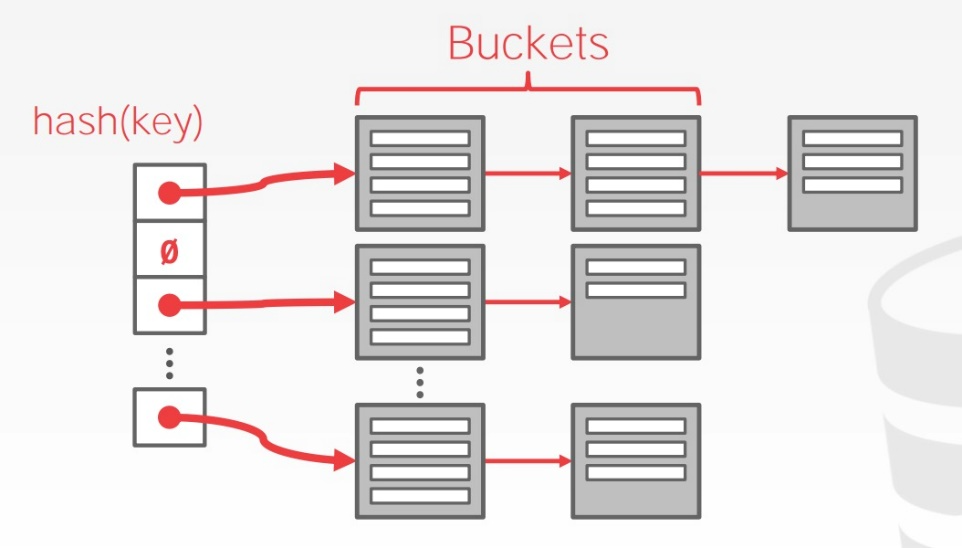
- 这么做的好处就是简单,坏处就是最坏的情况下 Hash Table 可能降级成链表,使得操作的时间复杂度降格为 O(n) 。
- 拓展哈希表(Extendible Hashing)
- 基于链式哈希,可以扩展overflow的chain

- 线性散列(Linear Hashing)
- 链式哈希(Chained Hashing)
- 上述Extendible Hashing是指数级的扩张hash表的,这未免也太快了。所以便有了LINEAR HASHING,线性扩张hash表,即每次只增加一个。其基本思想是维护一个指针split pointer,其指向下一个被拆分bucket,当任意bucket溢出时,将指针指向的当前bucket的拆分。
